从 Basic Block 到 Control Flow Graph
注意:三地址码是 Basic Block(BB)的基础,而 Basic Block 是 Control Flow Graph(CFG) 的基础,因此在阅读本文之前,你最好了解一下三地址码,可以参考我写好的上一篇博客
Basic Block (BB)
BB 是什么
flowchart
subgraph tac [Three-Address Code]
subgraph bb1 [Basic Block 1]
direction TB
instruction1
instruction2
end
subgraph bb2 [Basic Block 2]
direction TB
instruction3
instruction4
instruction5
end
end
得到一段程序的三地址码表示之后,就可以将它转化为 Basic Block (BB) 列表,每个 Basic Block 都包含最长且连续的三地址码指令,如上所示。并且每个 Basic Block 满足如下的条件
- 只有一个入口,为 BB 的第一条三地址码指令
- 只有一个出口,为 BB 的最后一条三地址码指令
如何得到 BB
输入:程序的所有三地址码指令
输出:Basic Block 列表
算法:
- 确定 Leader,这里 Leader 的意思是每一个 BB 的第一条指令
- 输入的第一条指令是 Leader
- 任何跳转指令(条件跳转/无条件跳转)的目标指令是 Leader
- 任何跳转指令(条件跳转/无条件跳转)的下一条指令是 Leader
- 根据 Leader 对输入进行分块,就得到了 BB 列表
- 可选:本来三地址码跳转指令的跳转目标都是指令,一般会将其改为 BB 的序号。能这么替换的原因是:BB 只有 1 个入口和 1 个出口
以 LLVM IR 为例
仍然沿用上一篇博客里面的例子,假设要分析的是下面这一段 C/C++ 代码(main.cpp)
int main() {
int sum = 0;
for (int i = 0; i < 10; i++) {
sum += i;
}
return 0;
}用 clang 导出 LLVM IR,命令如下
$ clang -S -emit-llvm main.cpp这里我从导出的 LLVM IR 代码里面提取出所有的指令,并给每一条指令分配了格式为 (i) 的序号
(1) %1 = alloca i32
(2) %2 = alloca i32
(3) %3 = alloca i32
(4) store i32 0, ptr %1
(5) store i32 0, ptr %2
(6) store i32 0, ptr %3
(7) br label (8)
(8) %5 = load i32, ptr %3
(9) %6 = icmp slt i32 %5, 10
(10) br i1 %6, label (11), label (20)
(11) %8 = load i32, ptr %3
(12) %9 = load i32, ptr %2
(13) %10 = add nsw i32 %9, %8
(14) store i32 %10, ptr %2
(15) br label (16)
(16) %12 = load i32, ptr %3
(17) %13 = add nsw i32 %12, 1
(18) store i32 %13, ptr %3
(19) br label (8)
(20) ret i32 0根据前面的算法,这里要先找到 Leader
- 第一条指令是 Leader,即
(1) - 任何跳转指令的目标是 Leader,即
(8), (11), (20), (16) - 任何跳转指令的下一条指令是 Leader,即
(8), (11), (16), (20)
去重一下就得到了 (1), (8), (11), (16), (20),那么上面的代码就可以划分为如下的 BB
(1) %1 = alloca i32
(2) %2 = alloca i32
(3) %3 = alloca i32
(4) store i32 0, ptr %1
(5) store i32 0, ptr %2
(6) store i32 0, ptr %3
(7) br label (8)
(8) %5 = load i32, ptr %3
(9) %6 = icmp slt i32 %5, 10
(10) br i1 %6, label (11), label (20)
(11) %8 = load i32, ptr %3
(12) %9 = load i32, ptr %2
(13) %10 = add nsw i32 %9, %8
(14) store i32 %10, ptr %2
(15) br label (16)
(16) %12 = load i32, ptr %3
(17) %13 = add nsw i32 %12, 1
(18) store i32 %13, ptr %3
(19) br label (8)
(20) ret i32 0那么这样对不对呢?,从 clang 导出的原始 LLVM IR 可以看出,这是正确的 :)
define noundef i32 @main() #0 {
0: ; this line is added by me to make it more explicit
%1 = alloca i32
%2 = alloca i32 ; %2 is sum
%3 = alloca i32 ; %3 is i
store i32 0, ptr %1
store i32 0, ptr %2 ; sum = 0
store i32 0, ptr %3 ; i = 0
br label %4 ; jump to %4
4: ; preds = %11, %0
%5 = load i32, ptr %3 ; load i
%6 = icmp slt i32 %5, 10 ; %6 = check if i < 10
br i1 %6, label %7, label %14 ; conditional jump based on if %6 is true
7: ; preds = %4
%8 = load i32, ptr %3 ; i
%9 = load i32, ptr %2 ; sum
%10 = add nsw i32 %9, %8 ; temp = sum + i
store i32 %10, ptr %2 ; sum = temp
br label %11 ; jump to %11
11: ; preds = %7
%12 = load i32, ptr %3 ; i
%13 = add nsw i32 %12, 1 ; temp = i++
store i32 %13, ptr %3 ; i = temp
br label %4 ; jump to %4
14: ; preds = %4
ret i32 0 ; return 0
}在 LLVM IR 里面,跳转指令的跳转目标 label 也可以是自动生成的数字(例子中的 %0, %4, %7, %11, %14),这个和我们前面提到的 (1), (8), (11), (16), (20) 是对应的
Control Flow Graph (CFG)
CFG 是什么
CFG 是一种图结构的 IR,是很多静态程序分析的基础,它的构成是
- 节点:一般是 BB。但有时候则是三地址码的一条指令1
- 边:箭头的方向表示控制的转移,或者说代码可能沿着这条边继续执行
如果用图来表示,那么就是
flowchart TB
subgraph CFG [Control Flow Graph]
bb1(Basic Block 1)
bb2(Basic Block 2)
bb3(Basic Block 3)
bb4(Basic Block 4)
bb1 --> bb2 & bb3
bb2 & bb3 --> bb4
end
如何得到 CFG
输入:BB 列表,用 $B_i$ 表示第 $i$ 个 BB。注意 BB 代表的三地址码指令连起来跟本来程序的三地址码指令连起来有一样的顺序
输出:CFG
算法:
- 如果 $B_i$ 经由跳转指令(条件跳转/无条件跳转)到 $B_j$,则创建 $B_i\rightarrow B_j$ 这条边
- 如果 $B_j$ 本来就在 $B_i$ 后面而且 $B_i$ 的最后一条指令不是无条件跳转指令,那么也会创建 $B_i\rightarrow B_j$ 这条边
以 LLVM IR 为例
0: ; this line is added by me to make it more explicit
%1 = alloca i32
%2 = alloca i32 ; %2 is sum
%3 = alloca i32 ; %3 is i
store i32 0, ptr %1
store i32 0, ptr %2 ; sum = 0
store i32 0, ptr %3 ; i = 0
br label %4 ; jump to %4
4: ; preds = %11, %0
%5 = load i32, ptr %3 ; load i
%6 = icmp slt i32 %5, 10 ; %6 = check if i < 10
br i1 %6, label %7, label %14 ; conditional jump based on if %6 is true
7: ; preds = %4
%8 = load i32, ptr %3 ; i
%9 = load i32, ptr %2 ; sum
%10 = add nsw i32 %9, %8 ; temp = sum + i
store i32 %10, ptr %2 ; sum = temp
br label %11 ; jump to %11
11: ; preds = %7
%12 = load i32, ptr %3 ; i
%13 = add nsw i32 %12, 1 ; temp = i++
store i32 %13, ptr %3 ; i = temp
br label %4 ; jump to %4
14: ; preds = %4
ret i32 0 ; return 0继续沿用前面的 LLVM IR 的例子,在前面的例子中,我们已经得到了所有的 BB 列表,接下来要解决的就是如何加边然后构造 CFG。按照算法流程:
- 检查所有的跳转指令
%0跳转到%4,因此有%0 -> %4%4可能跳转到%7, %14,因此有%4 -> %7和%4 -> %14%7跳转到%11,因此有%7 -> %11%11跳转到%4,因此有%11 -> %4
- 检查条件跳转指令
%4的最后一条是条件跳转指令,%7跟在%4后面,因此有%4 -> %7
如何检验上面推导的关系对不对呢?其实在上面的 LLVM IR 里面已经给出了答案
0: ; this line is added by me to make it more explicit
... ; omit
4: ; preds = %11, %0
... ; omit
7: ; preds = %4
... ; omit
11: ; preds = %7
... ; omit
14: ; preds = %4
... ; omit在代码的注释里面,它说 %4 的前驱(predecessor)是 %11 和 %0,这和我们的推导是一致的,剩下的也都符合
最后,我们可以用 clang 和 opt 导出 CFG 感受一下
$ clang -Xclang -disable-O0-optnone -S -emit-llvm main.cpp -o main.ll
$ opt -passes='dot-cfg' main.ll
$ dot -Tpdf .main.dot -o result.pdf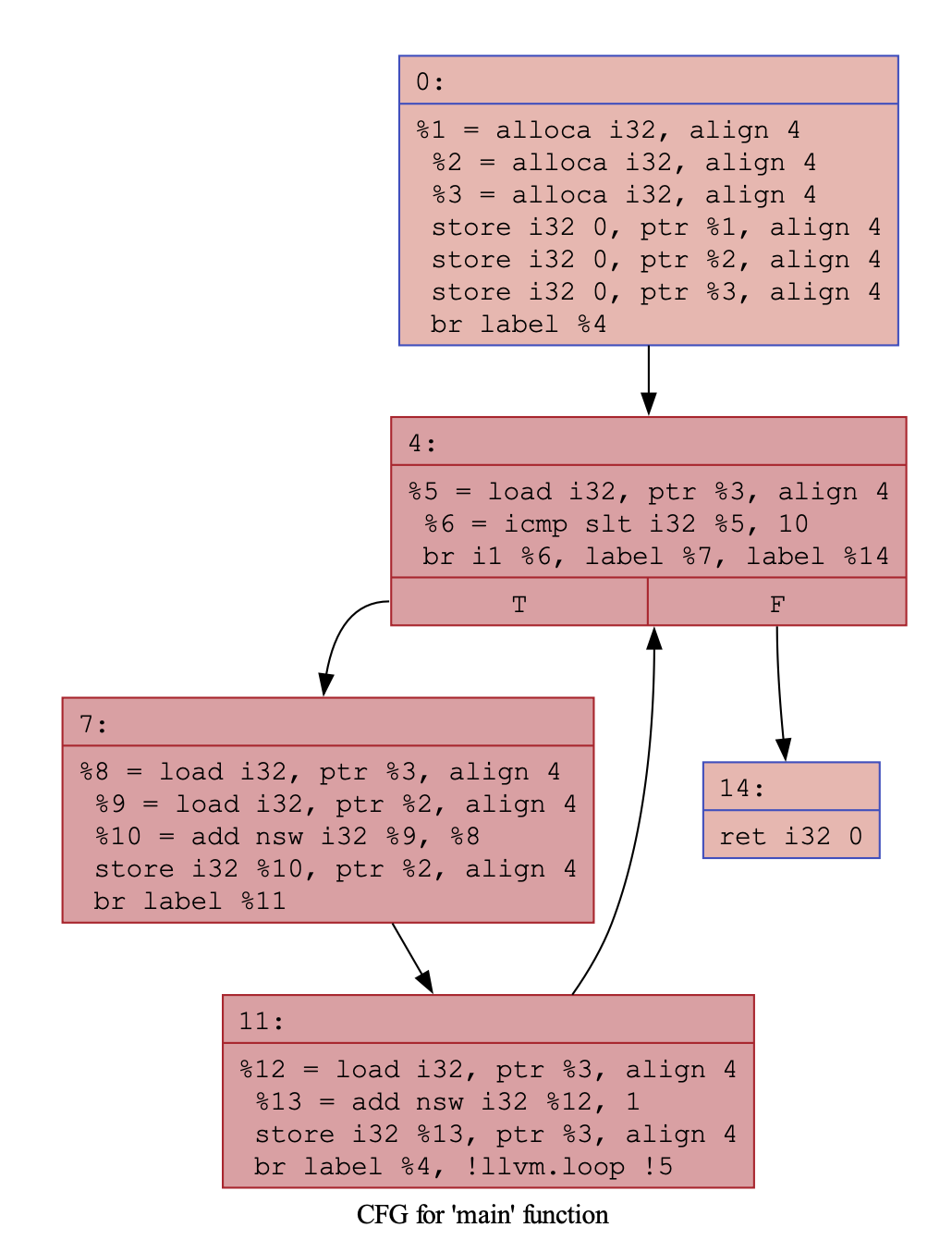
总结
以上就是本文的全部内容,通过同一个例子,从三地址码到 Basic Block,再到 CFG,这一条线算是串起来了。而有了 CFG 之后,后面要做数据流分析等程序分析就比较容易了~