LLM 推理加速技术(1):KV Cache
更新:
- 2026-03-28,使用更贴切的术语(Prefill、Decode);增加了时间复杂度的对比
背景
LLM 用于推理的时候有 2 个阶段(不开启 KV Cache 时)
- Prefill 阶段:输入是当前所有 token(完整的 Prompt),做前向传播,同时计算所有 token 的 Q/K/V
- Decode 阶段:输入是当前所有 token,做前向传播,同时计算所有 token 的 Q/K/V,生成下一个 token
假设现在已经生成了 $t$ 个 token,用 $x_{1:t}$ 表示。在下一轮,LLM 会生成 $x_{1:t+1}$,注意他们的前 $t$ 个 token 是一样的
$$ x_{1:t+1}=\text{LLM}(x_{1:t}) $$
再下一步也是相似的
$$ x_{1:t+2}=\text{LLM}(x_{1:t+1}) $$
概括来说,每一轮用上一轮的输出当成新的输入让 LLM 预测,一般这个过程会持续到输出达到提前设定的最大长度或者是 LLM 自己生成了特殊的结束 token
KV Cache 原理
LLM 的推理过程很好理解,但是这个简单的实现存在一个问题——存在不少的重复计算导致计算效率不是很高🧐
只需要看 LLM 的连续两次前向传播推理计算就很好理解为什么说存在重复计算了
比如考虑下面这一步
$$ x_{1:t+1}=\text{LLM}(x_{1:t}) $$
LLM 的输入是 $x_{1:t}$,先只看最后一个 token $x_t$,它的 query 向量会和前面的每个 token 以及自己产生的 key 向量计算内积
$$ \mathbf q_{t}^T\mathbf k_{1},\mathbf q_{t}^T\mathbf k_{2},…,\mathbf q_{t}^T\mathbf k_{t} $$
然后看下一步
$$ x_{1:t+2}=\text{LLM}(x_{1:t+1}) $$
LLM 的输入是 $x_{1:t+1}$,看最后一个 token $x_{t+1}$,它的 query 向量也会和前面的每个 token 以及自己产生的 key 向量计算内积
$$ \mathbf q_{t+1}^T\mathbf k_{1},\mathbf q_{t+1}^T\mathbf k_{2},…,\mathbf q_{t+1}^T\mathbf k_{t+1} $$
此时考虑 $x_{t+1}$ 的前一个 token $x_t$,它也要经历类似的步骤(因为整个序列 $x_{1:t+1}$ 重新做了前向传播)
$$ \mathbf q_{t}^T\mathbf k_{1},\mathbf q_{t}^T\mathbf k_{2},…,\mathbf q_{t}^T\mathbf k_{t} $$
可以看到,这个计算完全和上一轮的计算重复了,对于在 $x_t$ 之前的 token 也是这个道理。我们需要重新计算得到 $x_{1:t}$ 的所有 key 向量和 value 向量,而这些向量的值其实是不会变的🧐。向量的值不会变是因为模型参数是固定的,输入的 Prefix 也不变。
那么我们只需要把之前 token 的 key 向量和 value 向量都缓存起来,那么就没有必要重复计算了,这就是 KV Cache 的核心思想
在运用了 KV Cache 之后,除了第一轮(prefill 阶段)以外的每一轮,我们都只需要关注输入的最后一个 token,用这个 token 计算得到它的 query, key, value 向量,然后拿着这三个新向量和之前所有缓存的 key/value 向量计算自注意力
我画了一个示意图来帮助理解开启 KV Cache 之后发生了什么,考虑 LLM 从无到有开始生成 4 个 token,其中蓝色的部分表示 KV Cache 里面缓存的值;红色则表示没有被缓存
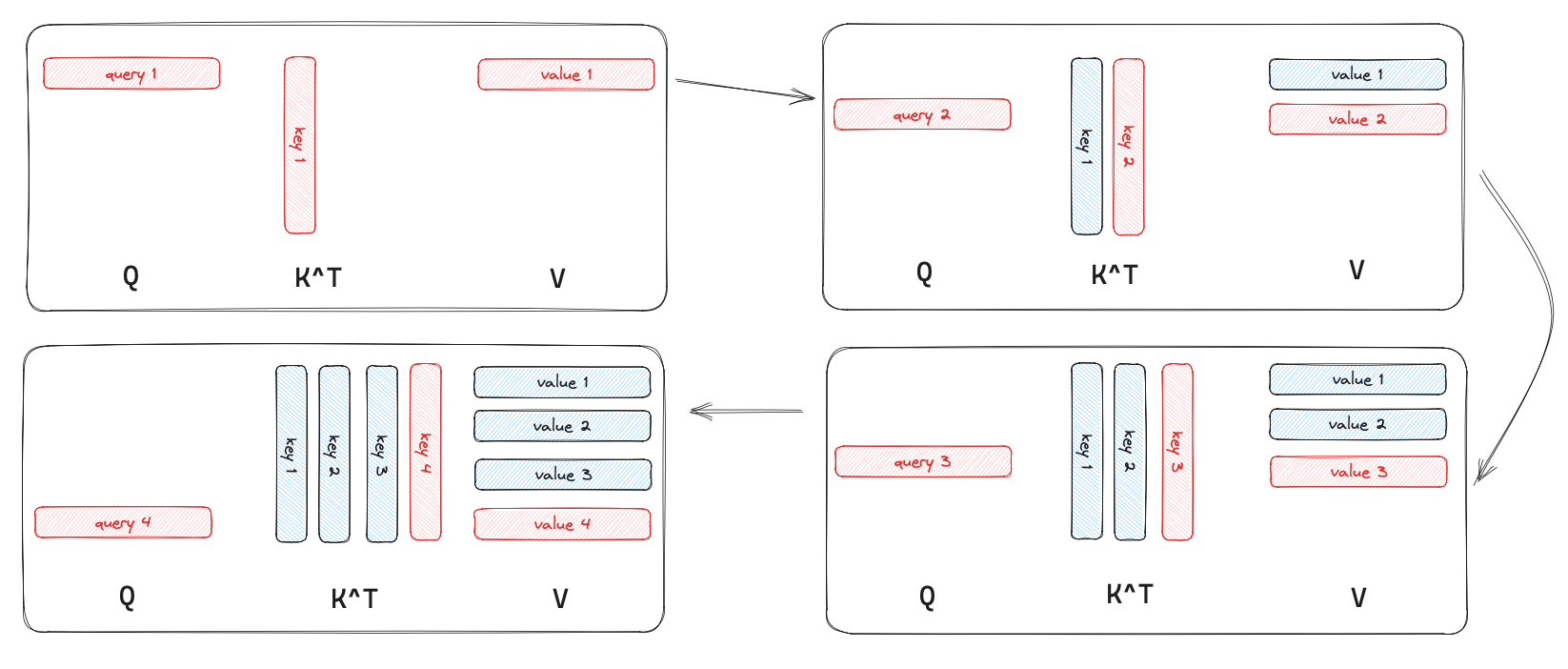
KV Cache 的效率分析
KV Cache 加速推理的原理是:在自注意力层,本来每次要做矩阵乘法 $\mathbf Q\mathbf K^T$,现在因为 KV Cache 的存在,我们不需要整个 $\mathbf Q$ 和 $\mathbf K^T$ 做矩阵乘法,只需要每次输入的最后一个 token 的 query 向量 $\mathbf q$ 和 $\mathbf K$ 做向量 - 矩阵乘法,之后更新 KV Cache 缓存即可
采用了 KV Cache 的话 LLM 的推理过程的 2 个阶段是这样子的
- Prefill 阶段:输入是当前所有 token(完整的 Prompt),做前向传播,同时计算所有 token 的 Q/K/V 并缓存 K 和 V
- Decode 阶段:输入是上一步生成的 token,只会为该 token 计算 query、key、value,根据历史缓存的 KV Cache 计算当前 token 的输出,并追加新的 key 和 value 向量到 KV Cache
KV Cache 加速推理的代价是显存占用会变高,所以它是空间换时间的办法,当你使用 KV Cache 的时候,显存开销大概是
$$ 2 \times \texttt{hidden size} \times \texttt{num layers} \times \texttt{seq len} $$
其中
2:因为要存储 key 和 value 向量hidden size:key 和 value 向量的长度num layers:每一层都要缓存 key、value 向量seq len:当前序列长度
当你不使用 KV Cache 的时候
- Decode 阶段每一步都需要重新计算所有历史 token 的 key、value、query 向量
- 显存占用更低(不会随着当前序列长度
seq len而增加),但是计算成本更高了
关于计算我们也可以稍加分析 KV Cache 关闭和开启的时间复杂度是多少,前面提到,KV Cache 的主要贡献是在 Decode 阶段的时候把矩阵 - 矩阵乘法变成了向量 - 矩阵乘法。如果我们将 hidden size 看成一个常数,那么每一步生成 token 计算复杂度从
$$ O(n^2)\rightarrow O(n) $$
还是很可观的一个推理优化 :)
KV Cache API
Huggingface 的 model.generate API 有一个参数为 use_cache,可以用来控制是否开启 KV Cache,这个选项是默认打开的1
总结
这里放一个开关 KV Cache 的快速对比表格,覆盖了本篇文章谈到的内容
| ❌️ KV Cache | ✅️ KV Cache | |
|---|---|---|
| Prefill 阶段 | 完整前向传播 | 完整前向传播,建立 KV Cache |
| Decode 阶段 | 完整前向传播 | 仅新 token 做前向传播,复用已有 KV Cache |
| 时间复杂度 | $O(N^2)$ | $O(N)$ |