Drain: 简单有效的日志解析算法
研究背景
很多云平台都有各种日志,但是并不是结构化的,但利用机器学习/数据挖掘从日志中挖掘信息的时候又希望输入是结构化数据
因此,如何从非结构化日志中提取结构化信息是一件很重要的事情,一个朴素的想法是:使用正则表达式自己做解析提取,但是这个方法有很多缺点1
- 日志的量太多,肉眼看日志然后写正则表达式不可取
- 日志来自系统里的每一个组件,每一个组件背后的开发者可能都有自己的写日志习惯,一个个适配太麻烦
在 Drain 算法被提出的时候(2017 年),很多日志解析手段都聚焦于离线批处理场景,但云平台的日志经常都是流式产生的,因此 Drain 算法聚焦在线流式处理场景,它可以自动从非结构化日志中挖掘日志模板,从而得到结构化数据
问题特点
一般来说,每一条日志可以看成日志元数据 + 日志信息。比如下面我用 loguru 打印的 Hello World 日志
2026-04-18 20:43:37.417 | INFO | __main__:<module>:3 - Hello World它大体上可以分为
- 日志元数据
- 时间戳:
2026-04-18 20:43:37.417 - 日志等级:
INFO - Python 模块和函数上下文:
__main__:<module> - 打印语句所在行号:
3
- 时间戳:
- 日志信息:
Hello World
所以整体上 loguru 的默认日志模板是
<时间戳> | <日志等级> | <Python模块和函数上下文>:<行号> - <日志信息>日志解析关心的是 <日志信息> 的部分,我们希望自动化挖掘日志模板,将日志进行分类
为了方便后续进行算法描述,这里规定几个术语
- Log Entry:每一行日志称之为 Log Entry
- Log ID:每一行日志都有唯一的 ID,比如行号就可以作为日志的 ID
- Log Event:日志模板,日志解析问题想要自动挖掘的
- Log Group:同一个 Group 内的日志遵循一样的 Log Event
- Log Message:日志解析的分析对象,是日志里的可变部分,即
<日志信息>
Drain 算法
Parse Tree
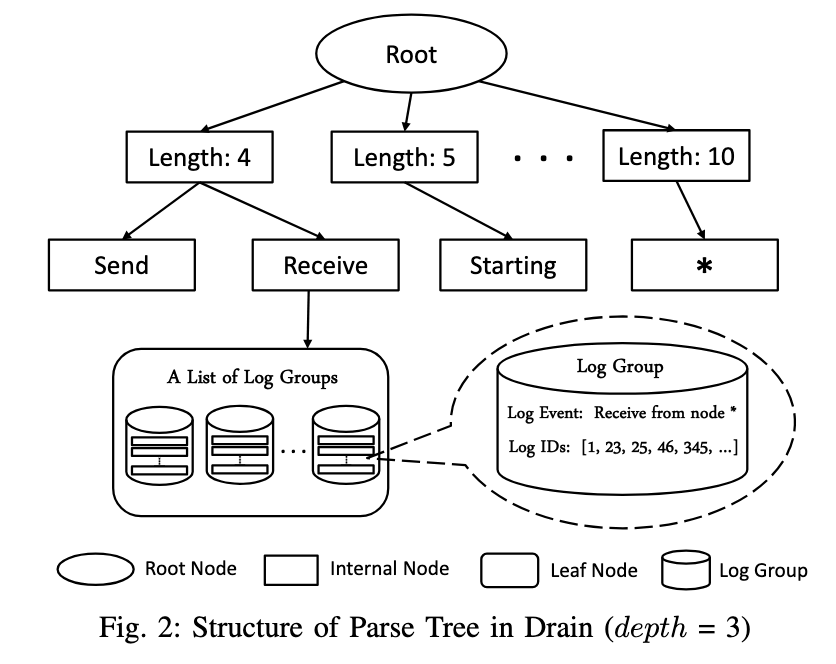
在正式谈论 Drain 算法之前,先来看 Drain 算法依赖什么核心数据结构——Parse Tree,本质是前缀树,前缀树上的节点可以分成
- 非叶子节点:从根节点出发到某个非叶子节点形成了一个“前缀”,比如图中的
Receive非叶子节点对应root -> length 4 -> Receive这个前缀 - 叶子节点:每个叶子节点指向了一个 Log Groups 列表,每个 Log Group 存储了一个 Log Event 和所有属于这个 Log Event 的日志的 Log ID。
根据前缀树的性质,可以确定的是:叶子节点指向的所有 Log Group 一定是共享前缀的
算法流程
输入:
- 日志文件,可以看成是一个 Log Entry 的列表
maxDepth- 用于控制 Parse Tree 的最大深度maxChild- 用于控制 Parse Tree 的每个节点的最大孩子数量st- 用于判断 Log Group 和输入是否匹配,是相似度的阈值
输出:一个 Parse Tree
算法
- 根据专家知识定义预处理规则(可选):根据专家知识,提前制定规则
- 可以提前指定每一条 Log Entry 的格式(比如用户指定
<Date> <Component> <Content>,<Content>表示的是 Log Message),用于自动确定一条日志信息里的 Log Message - 用户可以指定正则表达式对 Log Message 的部分内容进行替换。举个例子:
connect to node 3vsconnect to node 5,他们只是在数字上不同,但是理论上应该放在同一个 Log Group 里。可以定义r"\b\d+\b"检测孤立数字并替换为<*>,此时他们都变成connect to node <*>这种形式。无意义差异被抹除之后,这样他们在 Parse Tree 里面就会被分到同一个 Log Group 里。常见的替换项有 IP 地址、孤立数字等
- 可以提前指定每一条 Log Entry 的格式(比如用户指定
- 处理每个 Log Entry
- 使用定义的规则(若有)从 Log Entry 提取 Log Message
- 使用定义的正则表达式(若有)替换 Log Message 的内容
- 在 Parse Tree 上寻找匹配
- 使用空格对 Log Message 进行分词,切分成一个个 token
- 第一层:根据 token 数量(长度)在 Parse Tree 上选择对应的分支
- 后续层:按照 token 的实际内容逐层匹配(只看前
maxDepth - 2个 Token,-2是因为根节点、第一层不是按照 token 内容) - 最后走到某个叶子节点,叶子节点存放了若干候选 Log Group
- 和每一个候选 Log Group 计算相似度,相似度的定义是两个 token 序列中相同位置上相同 token 的比例
- 如果最大相似度
st,那么就认为找到了匹配
- 更新 Parse Tree:
- 上一步找到了匹配:将当前日志和匹配的 Log Event 逐 token 对齐,相同的保留。不一样的就更新该位置为
<*>,对 Log Event 进行泛化。举个例子- 更新前的 Log Event:
connect to node 3 - 当前日志:
connect to node 4 - 更新后的 Log Event:
connect to node *
- 更新前的 Log Event:
- 上一步没有找到匹配: 按该日志的 token 路径创建新节点(如果不存在),并在叶子节点新增一个 Log Group,其模板即为该日志本身
- 上一步找到了匹配:将当前日志和匹配的 Log Event 逐 token 对齐,相同的保留。不一样的就更新该位置为
值得一提的是,因为存在 maxChild 的限制,每一层都会有一个 <*> 节点,用于存放所有可能的匹配
端到端的例子
logparser 仓库提供了 Drain 算法的实现(代码仅 370 行左右),并且提供了相关的算法 Demo,下面我们使用该仓库下的 HDFS_2K 日志作为例子进行讲解,这是我从日志里节选的几行
[1] 081109 203615 148 INFO dfs.DataNode$PacketResponder: PacketResponder 1 for block blk_38865049064139660 terminating
[2] 081109 203807 222 INFO dfs.DataNode$PacketResponder: PacketResponder 0 for block blk_-6952295868487656571 terminating
[3] 081110 103657 32 INFO dfs.FSNamesystem: BLOCK* NameSystem.allocateBlock: /user/root/rand/_temporary/_task_200811101024_0001_m_000097_0/part-00097. blk_496376132244907301
[4] 081109 205931 13 INFO dfs.DataBlockScanner: Verification succeeded for blk_-4980916519894289629我们不难看出这些日志遵循如下的结构
'<Date> <Time> <Pid> <Level> <Component>: <Content>'其中的 <Content> 是我们关心的 Log Message,观察上述 Log Message 不难发现——其中无意义的数字遵循一定的模式,因此我们可以用 2 个正则表达式进行处理
r'blk_(|-)[0-9]+'- 处理blk_*r'(?<=[^A-Za-z0-9])(\-?\+?\d+)(?=[^A-Za-z0-9])|[0-9]+$'- 处理数字
[1] PacketResponder <*> for block <*> terminating
[2] PacketResponder <*> for block <*> terminating
[3] BLOCK* NameSystem.allocateBlock: /user/root/rand/_temporary/_task_<*>_<*>_m_<*>_<*>/part-<*>.<*>
[4] Verification succeeded for <*>接下来运行 Drain 算法(假设 maxDepth = 4, st = 0.5),一开始 Parse Tree 为空,解析第一条日志 PacketResponder <*> for block <*> terminating
- 按照空格分词可以得到
['PacketResponder', '<*>', 'for', 'block', '<*>', 'terminating'],长度为6 - Parse Tree 为空,直接返回不匹配,更新 Parse Tree
flowchart TB
root((root)) --> six((Length 6)) --> pr((PacketResponder)) --> four_star(("<*>")) --> group1("Packet Responder <*> for block <*> terminating")
接下来处理第二条日志 PacketResponder <*> for block <*> terminating,这一条跟上一条日志一样,相似度是 1 > 0.5 (st),因此会直接匹配上
直接看第三条日志:BLOCK* NameSystem.allocateBlock: /user/root/rand/_temporary/_task_<*>_<*>_m_<*>_<*>/part-<*>.<*>
- 按照空格分词可以得到
['BLOCK*', 'NameSystem.allocateBlock:', '/user/root/rand/_temporary/_task_<*>_<*>_m_<*>_<*>/part-<*>.', '<*>'],长度为11 - Parse Tree 的第一层不存在长度为
11的节点,返回不匹配,更新 Parse Tree,如下所示
flowchart TB
root --> el((Length 4)) --> block((BLOCK*)) --> ns((NameSystem.allocateBlock:)) --> group2(BLOCK* NameSystem.allocateBlock:/user/root/rand/_temporary/_task_<*>_<*>_m_<*>_<*>/part-<*>.<*>)
root((root)) --> six((Length 6)) --> pr((PacketResponder)) --> four_star(("<*>")) --> group1("Packet Responder <*> for block <*> terminating")
接下来看第四条日志:Verification succeeded for <*>
- 按照空格分词可以得到
['Verification', 'succeeded', 'for', '<*>'],长度为4 - Parse Tree 的第一层存在长度为
4的节点,但是不存在succeeded节点,返回不匹配,更新 Parse Tree,如下所示
flowchart TB
root --> el((Length 4)) --> block((BLOCK*)) --> ns((NameSystem.allocateBlock:)) --> group2(BLOCK* NameSystem.allocateBlock:/user/root/rand/_temporary/_task_<*>_<*>_m_<*>_<*>/part-<*>.<*>)
el --> succeeded((succeeded)) --> for((for)) -->group3(Verification succeeded for <*>)
root((root)) --> six((Length 6)) --> pr((PacketResponder)) --> four_star(("<*>")) --> group1("Packet Responder <*> for block <*> terminating")
后续的推导比较类似,这里就不重复了,你可以自行运行这个算法并通过打印日志的方式观察 Parse Tree 是如何一步步搭建起来的
总结
Drain 算法是面向日志解析的在线算法,其核心思想是基于前缀树对日志消息进行分层组织和快速匹配,它能够高效地将结构相似的日志归类到同一日志模板
-
Jiang Z, Huang J, Yu G, et al. L4: Diagnosing large-scale llm training failures via automated log analysis[C]//Proceedings of the 33rd ACM International Conference on the Foundations of Software Engineering. 2025: 51-63. ↩︎