论文阅读: REALM: Retrieval-Augmented Language Model Pre-Training
引言
最近打算系统性学习 RAG 技术,开始看起了相关文献,目前的思路是按照 ACL 2023 Tutorial 的 Roadmap 过一遍。本篇是对早期的 RAG 技术的 REALM 的介绍
本文采用的模型是 Masked LM 的 BERT,还不是 LLM。因此本文后续的部分内容需要你对 BERT 有一定的了解,包括 BERT 的预训练过程、BERT 微调等
The idea
Motivation 是这样子的:知识以参数的形式存储在模型里面,注意这是 implicit 的。本文提出可以在模型推理的时候,新增一个 Retriever,负责检索到跟输入相关的文本,来辅助模型推理
如果你对 BERT 很熟悉,应该还记得输入的限制最大为 512 个 token。因此这里的文本其实指的是 Text Chunk,论文里提到将文档都切成了一个个 Chunk
架构长下面这样 1
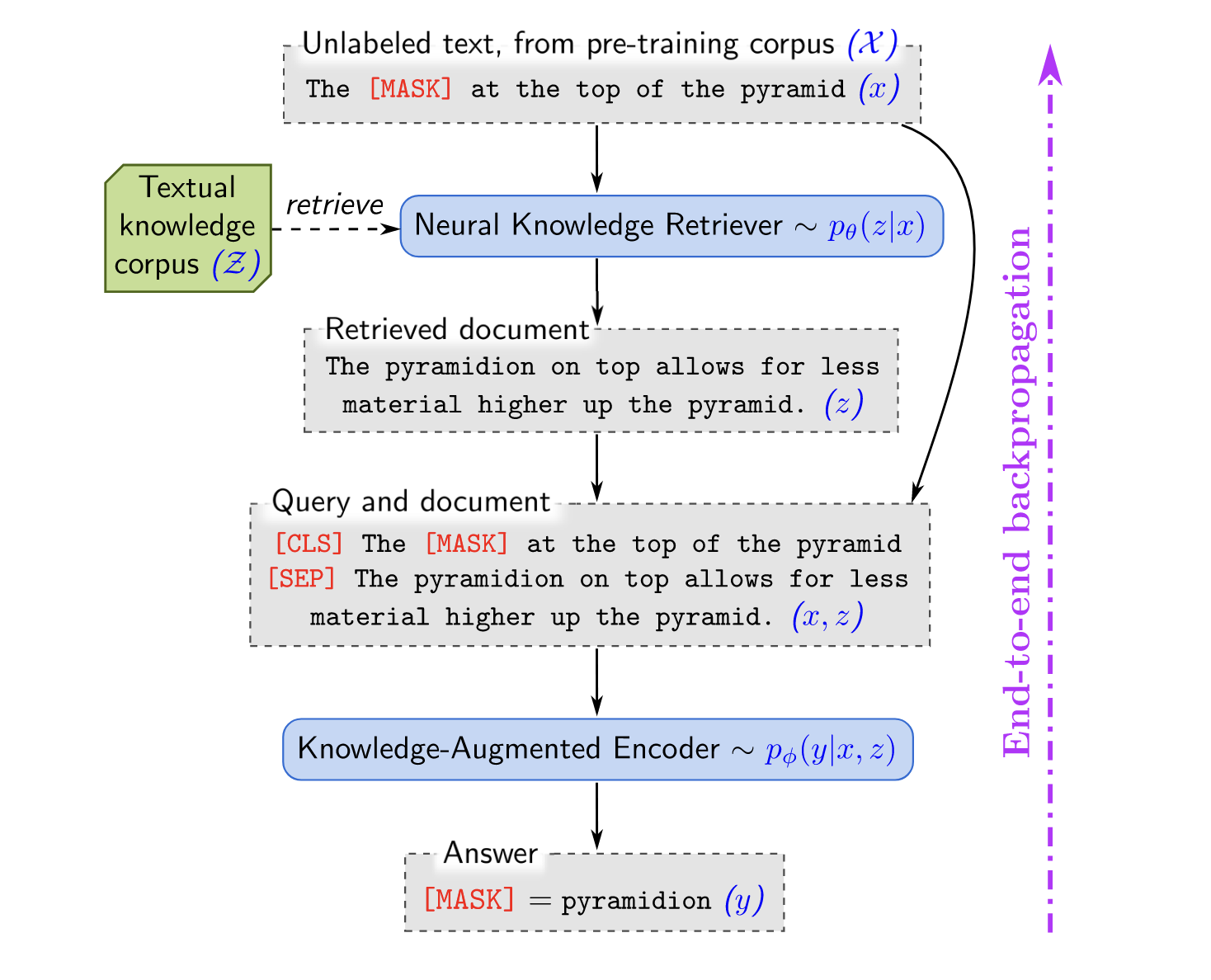
注意几点
- 这里的语言模型采用的是 BERT,所以可以看到
[CLS], [MASK], [SEP]这些特殊的 token - Retriever 取回的 Text Chunk 和本来的 Query 用
[SEP]拼接起来了
也就是现在多了一个 Retriever,那么就要处理几个问题
- 如何训练 Retriever?
- Retriever 要检查的语料库(图中的 $\mathcal Z$)特别大,如何高效做检索?
- Retriever 找到相关的 Text Chunk 之后要如何使用?
对于第一个问题,作者想到了 Unsupervised-Learning,用 Perplexity 作为“信号”,如果加上了 Retriever 检索到的 Text Chunk 之后会使得模型生成的 Text Chunk 的 Perplexity 提高,那么说明检索到的 Text Chunk 不好,反之则说明检索到了相关的 Text Chunk
对于第二个问题,每一个文档会被切分成一个个 Text Chunk,每一个 Text Chunk 都可以提前生成 Embedding,那么在得到 Query 的 Embedding 之后,只需要和每一个 Text Chunk 做向量内积,就可以计算相关性了
模型架构
记输入为 $x$,输出为 $y$,检索到的 Text Chunk 是 $z$,REALM 要做的事情就是给定输入预测输出,也就是
$$ p(y|x) $$
REALM 将其分为 2 步
- retrieve:从语料库 $\mathcal Z$ 里面检索 Text Chunk $z$,这可以建模为一个概率分布 $p(z|x)$
- predict:那么预测就是做条件生成,即 $p(y|z,x)$
根据前面的定义,我们需要解决的是 2 个公式的求解:$p(z|x),p(y|z,x)$,分别交给 Retriever 和 Encoder 负责,整体遵循 retrieve-then-predict 的思路
Retriever
先看 Retriever,负责处理 $p(z|x)$,即做 Text Chunk 的检索。公式计算方式为
$$ \begin{aligned} p(z|x)&=\frac{exp\ f(x,z)}{\sum_{z’}exp\ f(x,z’)} \\ f(x,z)&=\texttt{Embed}_{input}(x)^T\texttt{Embed}_{doc}(z) \end{aligned} $$
翻译成中文就是,得到输入的 Embedding $\texttt{Embed}_{input}(x)$,并计算语料库 $\mathcal Z$ 的每个 Text Chunk 的 Embedding,用输入的 Embedding 和每个Text Chunk 的 Embedding 分别做向量内积,$\texttt{softmax}$ 之后就可以得到概率分布,也就知道每一个 Text Chunk 跟输入的相关性
用 BERT 提取输入的 Embedding 的过程比较好理解,输出的 [CLS] 的 Embedding 一般被看成是输入的整体表示,作者还将其乘以一个权重矩阵做投影降维。核心问题是 Retriever 的输入是什么?
作者定义了如下的输入模板
$$ \begin{aligned} \texttt{join}_\texttt{BERT}(x)&=\texttt{[CLS]}x\texttt{[SEP]} \\ \texttt{join}_\texttt{BERT}(x_1,x_2)&=\texttt{[CLS]}x_1\texttt{[SEP]}x_2\texttt{[SEP]} \end{aligned} $$
- 对于 Query 来说,就是 $\texttt{join}_\texttt{BERT}(query)$
- 对于 Text Chunk 来说,就是 $\texttt{join}_\texttt{BERT}(z_{title}, z_{body})$。这里有点意思,title 和 body 分开,再用
[SEP]拼接起来
Encoder
Encoder 负责处理 $p(y|z,x)$,作者区分了预训练和微调 2 个场景,这里不对其进行展开。因为现在显然是 LLM 的时代了,我们看一下输入就好
$$ \texttt{join}_{\texttt{BERT}}(x, z_{\texttt{body}}) $$
模型训练
我们要优化的是 $p(y|x)$ 这个概率分布,希望给定输入 $x$ 的情况下,可以找到最相关的 $y$
现在多了一个 Text Chunk 检索的步骤,根据边缘概率有
$$ p(y|x)=\sum_{z\in\mathcal Z}p(y|z,x)p(z|x) $$
这里面有几个挑战
- $\sum_{z\in\mathcal Z}$ 说明我们需要对语料库里的每个 Text Chunk $z$ 都计算一下最后求和,Text Chunk 数量太多了怎么办?作者认为,取 Top-k 个,这是因为理想的情况下,很多 Text Chunk 都是无关的,所以 $p(z|x)\approx 0$
- Text Chunk 的 Embedding 可以提前计算,但问题是:随着 $\texttt{Embed}_{doc}$ 模型更新之后,原有的 Embedding 就不适用了,理想的情况下应该每次模型更新完成之后都更新一下 Text Chunk 的 Embedding,但这样会影响训练。针对不同的场合,作者提出了不同的方法
- 预训练:训练几百个 Step 之后再更新 $\texttt{Embed}_{doc}$ 的参数,然后刷新每个 Text Chunk 的索引,论文里说是 500 个 Step
- 微调:如果只是微调,那么不会更新 $\texttt{Embed}_{doc}$ 的参数
总结
2020 年提出的 REALM 是 BERT 模型下的 RAG 技术,虽然现在 BERT 已经不那么流行了,但 REALM 的 RAG 设计还是有值得借鉴的地方
- 在一开始就检索相关的 Text Chunk,而且只检索一次
- 当语料库太大的时候,选取 Top-k 个最相关的 Text Chunk 就可以了