什么是堆和栈
引言
如果你一直都是是用动态语言,比如 Python、Javascript 这种,你很可能并不会注意到栈和堆的区别。因为这些语言有垃圾收集器(Garbage collector,GC)存在,会自动帮你做好内存管理,你只要集中注意力编程即可。坏消息是 GC 并不是没有成本的事情,实际上设计再好的 GC 算法,也会降低代码的性能。如果你接触编程的时间足够久,那么想必你可能会听到过什么“递归层数太深栈爆炸了”这种话,此时你可能会点开搜索引擎稍微了解一下栈和堆的区别,有可能你就刚好点进了这一篇文章 :)
📒 虽然 GC 会降低代码性能,但是免去了开发人员手动管理内存的心智负担,可以大大加速软件开发的速度,这是牺牲性能换取开发速度。但到了软件后期出现性能瓶颈的时候,就不得不研究如何重构甚至重写关键部分的代码提高性能了。
这里的栈和堆并不是数据结构里面的堆和栈,而是指内存管理的两种机制。了解栈和堆的细节差异有助于我们理解一些比较接近底层的编程语言,这里说的编程语言比如 Rust、C 和 C++ 等。在 Rust 中,最为重要的概念就是所有权的问题,Rust 的很多设计都是围绕它展开,掌握了所有权就能在学习 Rust 的时候如鱼得水😄。
程序在内存上的布局
我们知道,要运行一个程序必须将程序加载到内存里面,在程序运行的过程中,数据也是需要读取到内存上的,那么你有没有想过这一切在内存上是如何分布的呢?下面我会给出一个比较简单的示意图1:如下所示:
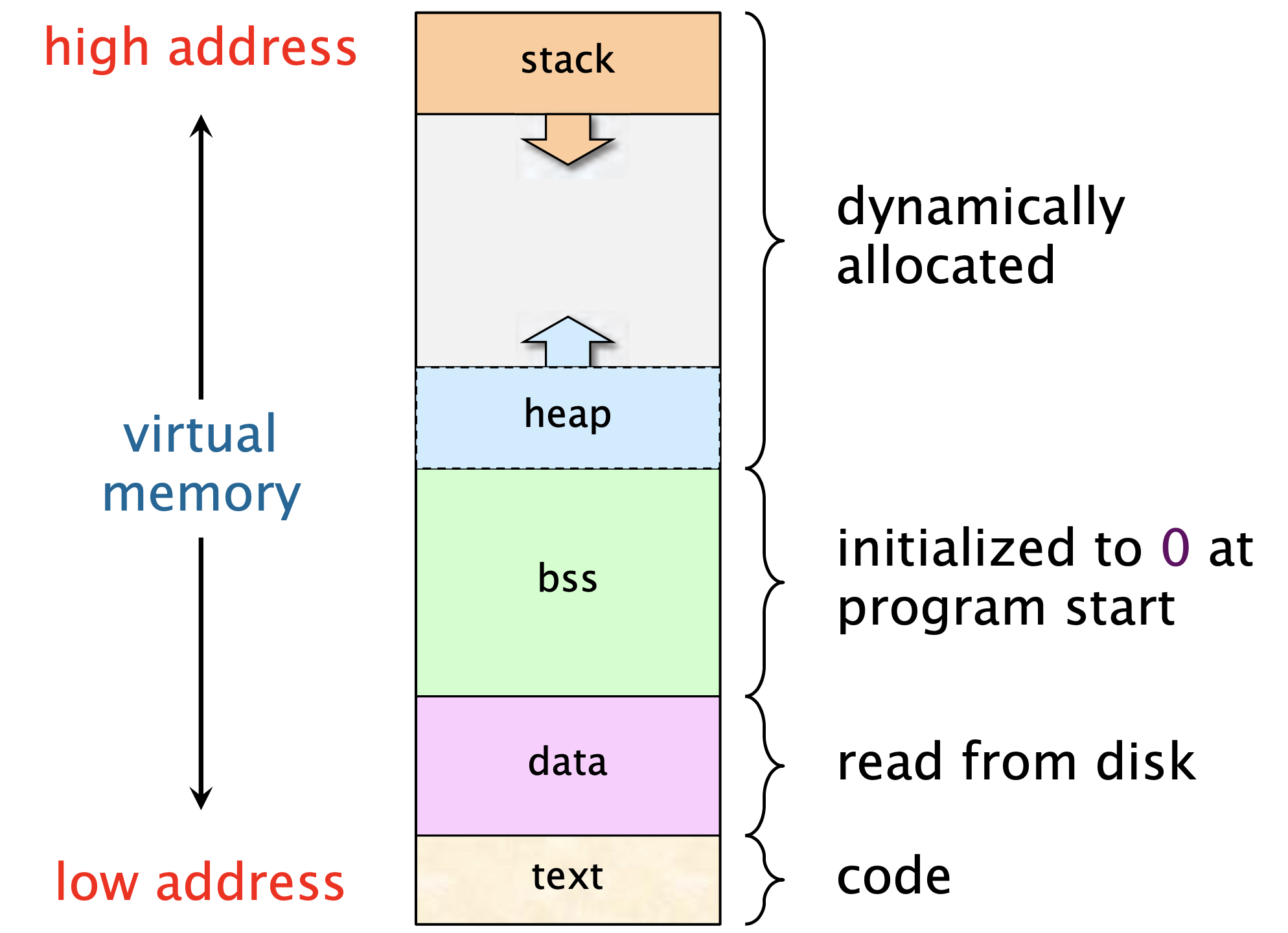
在上图中,不同部分存放的东西分别是:
- text:存放代码
- data:存放初始化过的静态变量(Initialized static variables),比如全局变量、静态变量
- bss:存放未经初始化的静态变量(Uninitialized static data),比如 C 语言的
static int i - heap
- stack
关于栈和堆会在后面进行单独说明
📒 这里要记住的就是:栈和堆是在向彼此靠近的,栈是从高地址 -> 低地址增长,而堆是低地址 -> 高地址增长。这样你在看汇编代码的时候看到入栈时 sp 指针是做减法你就能理解了。
📒 虽然看起来,随着我们申请内存越来越多,栈和堆可能会冲突(因为他们在彼此靠近),但是实际上并不需要担心这个问题,因为:1)这个布局是发生在虚拟内存上的,现在的处理器一般是 64 位的,容量非常大。2)在它们冲突之前,很有可能你的物理内存早就耗尽了,还是先担心这个
栈
术语
- Stack pointer(SP):实际上是一个寄存器,里面存放栈顶的地址
- Stack frame:当发生函数调用的时候就会创建 Stack frame。可以理解为它包含了函数调用的相关数据。比如函数的参数、函数的返回地址、函数的局部变量(除了分配在堆上的)等。一连串的 Stack frame 就构成了调用栈(Call stack)
- 入栈:在栈上申请空间
- 出栈:在栈上释放空间
栈上的内存管理是如何进行的
栈最大的特点就是先进后出(Last in first out, LIFO),这是我们在栈上申请空间和释放空间的时候的遵循的模式,这也是它叫做栈的原因。在内存上申请空间其实并不神秘,就是要标记哪些范围的地址是这个程序要用的。对栈来说,只要修改 stack pointer 的值即可,自然的,从栈底(下图中的 A)到栈顶(sp 指向的位置)就是我们栈上申请了的空间
下面的图1就展现了这个简单的逻辑:
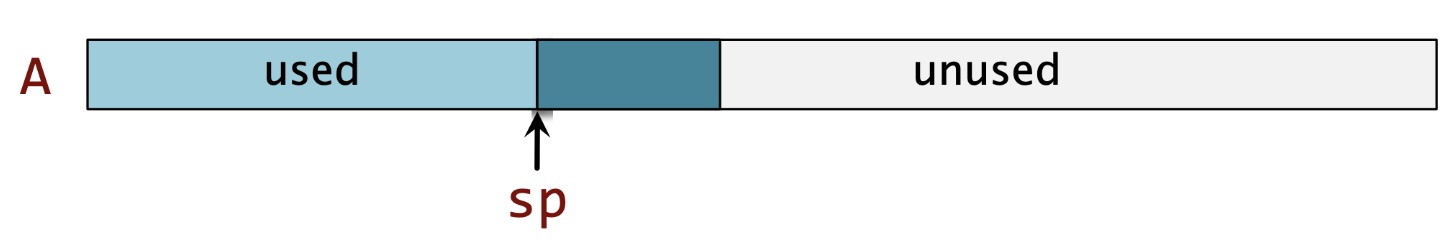
这里仍要再次强调,栈是从高地址 -> 低地址增长,所以上图从左到右是高地址 -> 低地址,所以在栈上申请空间(入栈)的时候实际上 sp 是做减法.
函数调用也是用栈完成的,简单来说:
- 调用函数的时候:修改
sp指针 -> 构造被调用的函数的 stack frame,其中包括函数参数和其他一些必要的数据,将其入栈 -> 进入 Callee - 函数退出的时候:上面的过程反过来就行
对这个过程的详细解释可以参考 2
📒 在栈上申请内存空间的时候需要担心的问题是:不要申请太多导致栈爆了(也就是大名鼎鼎的 Stack Overflow)。这一点在写递归函数的时候要特别注意。你可以选择改成迭代的算法,也可以考虑增加栈的大小限制。比如在 Python 里面可以用
sys.getrecursionlimit()来修改栈的大小限制。有的编程语言还会对尾递归进行优化,此时也可以选择将普通的递归函数改写为尾递归的形式。
以斐波那契数列的递归函数看栈的变化
CS 课程中讲解递归的时候一般都会讲到斐波那契数列,现在我们用 F(n) 表示斐波那契数列的第 n 个值,那么有:
F(0) = 0F(1) = 1F(n) = F(n - 1) + F(n - 2)
以 F(4) 为例,递归计算的方式如下:
F(4) = F(3) + F(2)
= F(2) + F(1) + F(1) + F(0)
= F(1) + F(0) + F(1) + F(1) + F(0)
= 3 * F(1) + 2 * F(0)如果我们忽略一些细节,感受函数调用的过程中栈的变化情况,那么大概如下所示:
注: 下面的 F(n) 表示每个函数自己的 stack frame
stack: F(4)
stack: F(4) | F(3) # F(4): enter F(3)
stack: F(4) | F(3) | F(2) # F(3): enter F(2)
stack: F(4) | F(3) | F(2) | F(1) # F(2): enter F(1), F(1) is the base case, ready to exit function call
stack: F(4) | F(3) | F(2) # Function return, return to the body of F(2)
stack: F(4) | F(3) | F(2) | F(0) # F(2): enter F(0), F(0) is the base case, ready to exit function call
stack: F(4) | F(3) | F(2) # Function return, return to the body of F(2)
stack: F(4) | F(3) | F(1) # F(3): enter F(1), F(1) is the base case, ready to exit function call
stack: F(4) | F(3) # Function return, return to the body of F(3)
stack: F(4) # Function return, return to the body of F(4)
stack: F(4) | F(2) # F(4): enter F(2)
stack: F(4) | F(2) | F(1) # F(2): enter F(1), F(1) is the base case, ready to exit function call
stack: F(4) | F(2) # Function return, return to the body of F(2)
stack: F(4) | F(2) | F(0) # F(2): enter F(0), F(0) is the base case, ready to exit function call
stack: F(4) | F(2) # Function return, return to the body of F(2)
stack: F(4) # Function return, return to the body of F(4)栈上存放的是什么数据
栈上的内存空间管理是通过修改 sp 指针的值实现的,很容易知道下面几点:
- 栈上的内存申请和释放都十分高效,为
O(1),只要修改sp的值即可 - 栈的这种 LIFO 的逻辑比较简单,编译器其实就能帮我们处理好,作为开发者我们不需要干预这个过程
- 修改
sp指针决定要申请多大的空间,意味着我们必须知道要申请的数据有多大(编译时要能确定),所以栈适合存放的数据是固定已知大小的。而大小不固定的数据是用堆来解决的
堆
栈的不足之处是:无法处理大小可变的数据,我们无法知道此时 sp 的值要修改为多少。
如何在大小可变的数据和栈之间搭建起桥梁呢?这就需要用到指针了。虽然实际存储的数据大小未知,但是指针的大小是固定已知的(只要保证寻址范围能覆盖到整个内存就行,一般跟机器字长相等),所以我们可以在栈上存储一个固定大小的指针,让这个它指向堆上存储的真正数据。
堆上的内存管理是如何进行的
正如前面提到的,在堆上申请内存其实就是在堆上找到一个足够大的空间,并返回这个位置的指针,而后指针入栈。
后面我们想要访问这个数据的时候,就对指针解引用即可。C 语言或者 Rust 里面的 * 操作符就是用来干这个的。不知道看到这里,以前难懂的指针是不是稍微能理解一点了 :)
不同于栈里面简单修改 sp 指针即可,堆上的内存管理复杂得多。包括下面几点:
- 堆上可以分配的内存的位置是任意的、大小也是任意的(不超过物理内存大小即可),而栈只要遵循先进后出就行。为了管理堆上已分配和待分配堆空间,我们需要设计相应的算法和数据结构,这就给堆上的内存管理带来很大的困难
- 在堆上申请空间的效率也比较低。最基本的,我们起码要找到一个足够大小的空间,这个找的过程肯定是比直接修改
sp的值耗时的。 - 还要处理好「碎片化」的问题。因为堆上申请空间是这边分配一块那边分配一块,在重复的申请空间和释放空间的过程中,会在内存里面留下很多碎片。极端的情况是:碎片加起来的可分配大小满足你的要求,但是因为他们散落在内存各个地方无法利用从而导致了内存不足
📒 堆上可以分配的内存比较大,但是需要更良好的管理机制来处理这种比较复杂的情况。对开发人员来说,也造成了一定的负担,我们无法依赖编译器自动帮我们处理,而是要自己手动管理内存,比如在 C 语言中你进行了
malloc()函数申请空间之后要是忘记用free()释放,那么你的程序就会存在内存泄露的问题。更别谈还有其他的诸如悬垂指针等问题。
堆上存放的是什么数据
对堆上内存空间的分配有一定了解之后,我们不难得出下面的几个结论:
- 堆上存放的是容量可变的数据。更灵活的同时,代价是牺牲了一点性能
- 有时候也可以是固定大小的数据,但是你不想放在栈上。为什么会有这种情况?比如,在 Rust 里面,栈上的数据是默认生成拷贝,有时候出于性能的考量,你可能想要把很大的数据放在堆上,避免多次拷贝带来的开销。不知道看到这里你们有没有想到我们常常说函数参数传递引用比传递值效率更高这个优化呢?
总结
- 栈和堆都是内存管理里面的概念,他们跟数据结构里的栈和堆的概念不一样。栈之所以叫做栈是因为我们在进行内存申请和分配的时候都遵循 LIFO 模式,而堆这个名字则是体现了堆上面的数据毫无组织。
- 通常来说,在栈上申请和释放内存空间是比较高效的。为此,Rust 里面默认都是在栈上操作
- 栈上一般放「固定大小」的数据,堆上一般放「大小可变」的数据。但是有时候出于性能的考量,也会在堆上存放固定大小的数据
在 CS 这门学科里面,经常可以看到分层的设计,比如计算机网络的 OSI 模型。包括编程语言本身也可以分为高级语言和低级语言。6.172 性能工程的老师说的一句话分享给你们—— “很多时候你要学好这一层的东西是必须了解下面一层的东西,你不一定要会用下一层的东西,但是知道下一层的细节会帮助你学这一层”。至少对我来说,知道了栈和堆的区别之后,下面的几个问题在我看来有了很合理的解释:
- C/C++ 语言的指针是用来干什么的?他们为什么存在?
- 为什么尾递归优化会存在?为什么在写递归函数的时候都要考虑递归层数太深的问题?
- 为什么 Rust 默认数据放在栈上?
- 为什么以前会看到 C/C++ 传递函数参数的时候要用引用这种说法,说这样会比较快?
📒 在 CS 里面,我认为最重要的概念就是封装。逐层封装,对上一层隐藏细节的这种设计实在很不错。
选择带有 GC 好上手但效率较低的语言还是选择自己手动管理内存让代码效率更高呢?这点其实取决于你手头的工作。如果要开发速度当然是前者了,如果注重性能那就是后者。当然,夹在中间的是没有 GC + 基本不用自己手动管理内存 + 效率高的 Rust 语言🚀,要不学点 Rust😉
⚠️ 本文在组织的时候可以忽略了一些细节,我只讲了我认为比较重要的几点。如果想要了解更多,值得一看的材料参考下面的资料引用