LLM inference optimization (1): KV Cache
Updates:
- 2026-03-28: Introduced standard terminology (e.g., prefill, decode) and added time complexity analysis.
Background
LLM inference typically consists of two stages when generating tokens (when disabling the KV Cache)
- Prefill stage: During the initial forward pass, the model processes the entire input (prompt) and computes the Q/K/V representations for all input tokens in parallel.
- Decode stage: The model generates tokens autoregressively, producing each next token conditioned on all previously generated tokens. It still needs to process the entire input and compute the Q/K/V representations for all input tokens.
The secret behind LLM is that it will generate tokens one by one based on all the previous tokens.
Let’s assume that we have already generated $t$ tokens, denoted by $x_{1:t}$. In the next iteration, the LLM will generate $x_{1:t+1}$. Note that the first $t$ tokens are the same.
$$x_{1:t+1}=\text{LLM}(x_{1:t})$$
The next iteration is similar.
$$x_{1:t+2}=\text{LLM}(x_{1:t+1})$$
In summary, in each iteration, we will use the output of the previous round as a new input for the LLM. Generally, this process will continue until the output reaches the maximum length we predefined or the LLM itself generates a special token, signifying the completion of the generating process.
Demystify the KV Cache
The inference process of the LLM is easy to understand, but this simple implementation has a drawback - there is a significant amount of redundant computation🧐
Simply overserving two consecutive inference calculations is sufficient to understand why the redundant computations are present.
For example
$$ x_{1:t+1}=\text{LLM}(x_{1:t}) $$
The input of the LLM is $x_{1:t}$. Let’s focus on the last token $x_t$, whose query vector will undergo dot product computation with the key vectors generated by each of the preceding tokens, including itself.
$$\mathbf q_{t}^T\mathbf k_{1},\mathbf q_{t}^T\mathbf k_{2},…,\mathbf q_{t}^T\mathbf k_{t}$$
The next step is
$$ x_{1:t+2}=\text{LLM}(x_{1:t+1}) $$
The input of the LLM is $x_{1:t+1}$. The last token $x_{t+1}$ will also undergo dot product computation with the key vectors generated by each of the preceding tokens, including itself.
$$\mathbf q_{t+1}^T\mathbf k_{1},\mathbf q_{t+1}^T\mathbf k_{2},…,\mathbf q_{t+1}^T\mathbf k_{t+1}$$
What about the token $x_t$? It undergoes a similar computation, after which the sequence $x_{1:t+1}$ is fed forward through the model.
$$\mathbf q_{t}^T\mathbf k_{1},\mathbf q_{t}^T\mathbf k_{2},…,\mathbf q_{t}^T\mathbf k_{t}$$
We can see that the computations are redundant compared to the previous round. The same logic applies to tokens before $x_t$: we recompute the key and value vectors for $x_{1:t}$, even though they actually remain unchanged🧐. This is because the model parameters are fixed and the input prefix does not change.
What if we cached all the key vectors and value vectors for all preceding tokens? We won’t need to compute these again and again. That’s exactly what the KV Cache does.
After applying the KV Cache, in each round except the first one (prefill stage), we only need to focus on the last input token. We will compute its query, key, and value vectors and use these 3 new vectors to perform a self-attention operation with all the cached key/value vectors of preceding tokens.
I drew a simple picture to show what happened when we used the KV Cache to speed up the inference process. Consider that the LLM generates 4 tokens starting from scratch, where the blue part represents the values that are cached, and the red part indicates what’s not cached.
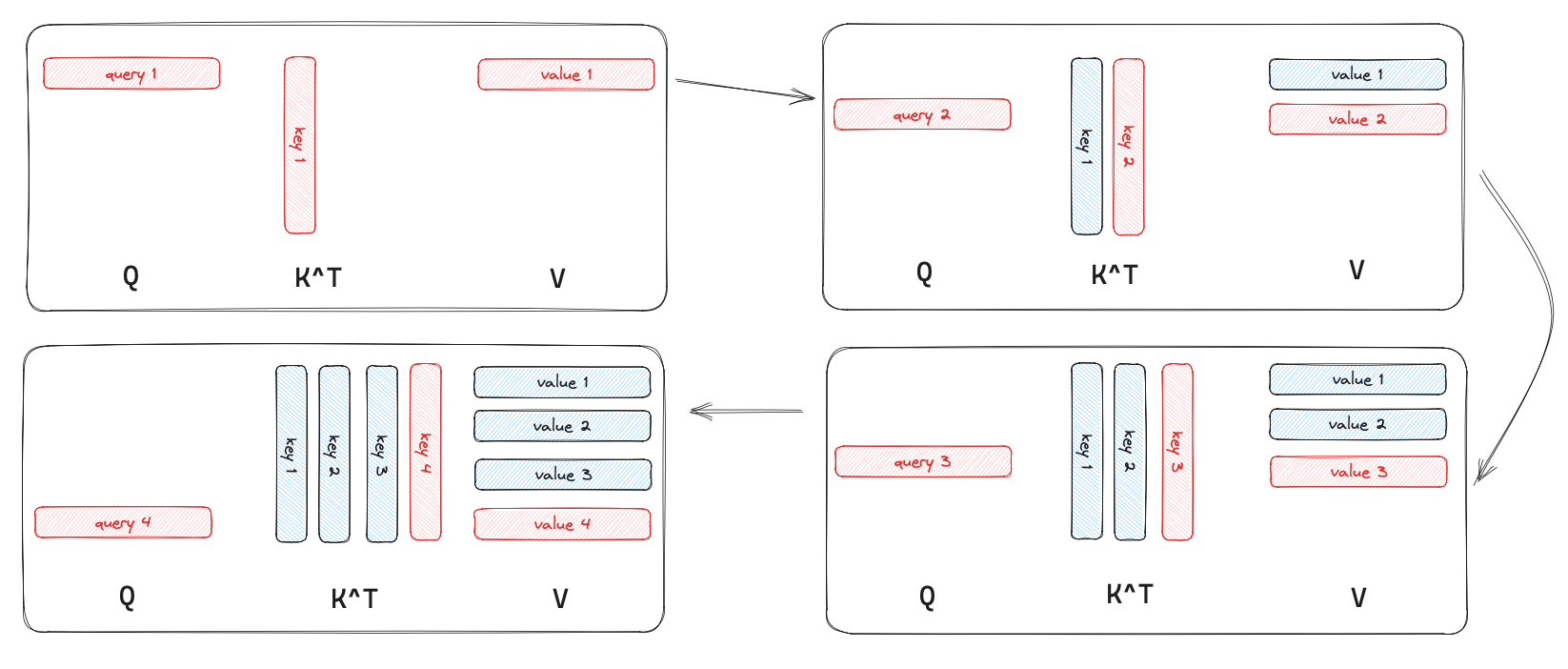
The performance of the KV Cache
The principle behind accelerating inference with the KV Cache is as follows: in the self-attention layer, instead of performing the matrix multiplication $\mathbf Q\mathbf K^T$ in each iteration, we only need to perform vector-matrix multiplication between the query vector $\mathbf q$ of the last token of each input and $\mathbf K$, and then we update the KV Cache.
After enabling the KV Cache, the two stages of LLM inference will change:
- Prefill stage: During the initial forward pass, the model processes the entire prompt and computes the Q/K/V representations for all input tokens in parallel. At the same time, it stores the K/V in the KV Cache.
- Decode stage: For each new token, the model computes its query, key, and value vectors, and appends the key and value vectors to the KV cache. The model still generates tokens autoregressively, but now uses the cached keys and values when computing attention. Notably, it no longer needs to perform a full forward pass over all previous tokens.
The trade-off for accelerating LLM inference is increased GPU memory usage. When the KV cache is enabled, the memory consumption can be approximated as:
$$ 2 \times \texttt{hidden size} \times \texttt{num layers} \times \texttt{seq len} $$
where
2: Both of the key and value vectors must be cached.hidden size: The size of the key and value vectors.num layers: The key and value vectors need to be cached in each layer.seq len: The current length of the input sequence.
When disabling the KV Cache
- The LLM needs to perform a full forward for input tokens.
- The memory consumption will be lower (it would not increase as the
seq lenincreases)
We can also briefly analyze the time complexity of the KV cache with and without caching. As mentioned earlier, the main contribution of KV cache is that, during the decode stage, it turns a matrix–matrix multiplication into a vector–matrix multiplication. If we treat hidden size as a constant, then the per-token generation complexity changes from:
$$
O(n^2)\rightarrow O(n)
$$
Quite a descent optimization :)
KV Cache API
Huggingface provides an API called model.generate. It has a parameter called use_cache, which is set to True by default1.
Wrap-up
A quick summary of this post:
| ❌️ KV Cache | ✅️ KV Cache | |
|---|---|---|
| Prefill stage | full forward | full forward, but create KV Cache |
| Decode stage | full forward | only forward new token, use KV Cache |
| Time complexity | $O(N^2)$ | $O(N)$ |