Drain: simgple but effective log parsing algorithm
Backgroup
Web service platforms generate a large volume of unstructured logs. However, machine learning and data analysis require structured input.
Therefore, extracting structured information from unstructured logs is a critical problem. A naive approach is to use regular expressions to extract structured information. However, this method has some drawbacks1
- The volume of logs is so large that manually crafting regex patterns is impractical.
- Logs may come from different components, each with its own log format.
The Drain algorithm was proposed in 2017. At that time, many log parsing algorithms focused on offline batch processing. However, logs in web service platforms are generated as a stream. Therefore, the drain algorithm focuses on online stream processing.
The characteristics of log parsing
A log entry can usually be divided into a log header and a log message. For example, considering the following log generated using the popular loguru library:
2026-04-18 20:43:37.417 | INFO | __main__:<module>:3 - Hello WorldWe can break it down into the following components:
- Log header
- Timestamp:
2026-04-18 20:43:37.417 - Log level:
INFO - Python module and function context:
__main__:<module> - Line number of logging statement:
3
- Timestamp:
- Log message:
Hello World
We can then infer a candidate log template as follows.
<Timestamp> | <Log level> | <Python module and function context>:<Line number> - <log message>The purpose of a log parsing algorithm is to mine log templates from <log message> automatically.
Before we delve into the Drain algorithm, we first define several key terms.
- Log Entry: A single log line.
- Log ID: A unique identifier assigned to each log entry.
- Log Event: The log template.
- Log Group: A group of log entries that share the same log event (template).
- Log Message: The part of the log that is relevant for parsing.
Drain algorithm
Parse Tree
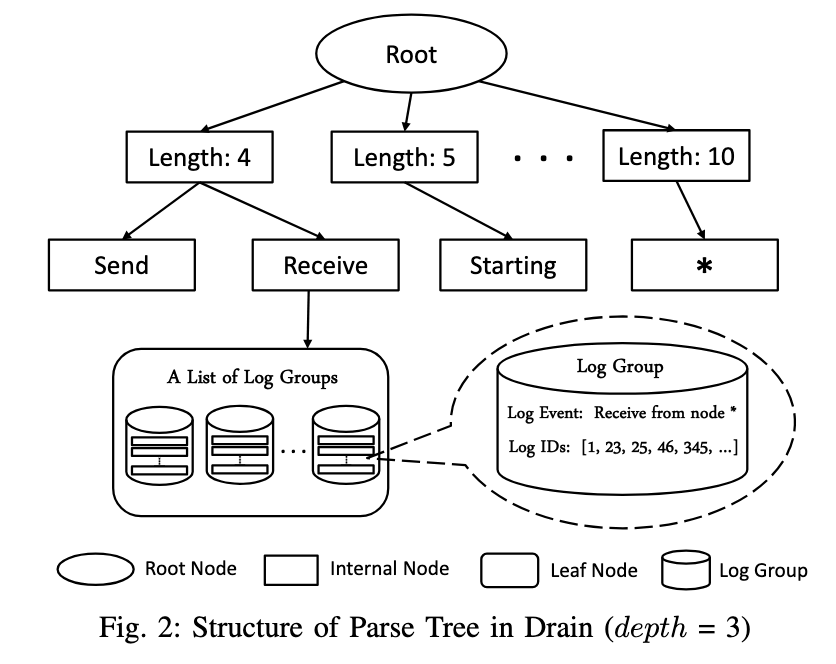
The Drain algorithm relies on a key data structure: a parse tree (i.e., a prefix tree). The nodes can be categorized as follows.
- Internal node: The path from the root node to an internal node defines a prefix. For example, the
Receiveinternal node represents theroot -> length 4 -> Receiveprefix. - Leaf node: Each leaf node points to a list of log groups. Each log group contains a log event and a log ID list.
By the property of the prefix tree, we know that: All log groups associated with the same leaf node share a common prefix
Algorithm
Inputs:
- A log file
maxDepth: the maximal depth of the parse tree.maxChild: the maximal number of children per node.st: the token similarity threshold when comparing input and each log group.
Outputs: a parse tree.
Algorithm:
- Define preprocessing rules based on domain knowledge (optional):
- The log entry format can be specified in advance, e.g.,
<Date> <Component> <Content>where<Content>denotes the log message. This helps the Drain algorithm identify the log message. - Regular expression patterns can be defined to normalize variable components in a log message. For example, the log messages
connect to node 3andconnect to node 5should belong to the same log group. The numeric identifiers are therefore abstracted. A pattern such asr"\b\d+\b"can be used to replace isolated digits with<*>, yieldingconnect to node <*>. Common normalization targets include IP addresses and numeric digits.
- The log entry format can be specified in advance, e.g.,
- Process each log entry
- Extract the log message from the log entry using pre-defined rules (if available).
- Normalize the log message using pre-defined rules (if available).
- Match against the parse tree
- Split the log message into tokens using whitespace, yielding a token sequence.
- First layer: Select the child node based on the length of the token sequence.
- Subsequent layers: Traverse the tree by consuming tokens sequentially. Only the first
maxDepth − 2tokens are used, since the root and the first layer do not correspond to tokens. - Finally, a leaf node may be reached, which maintains a list of log groups.
- For each candidate log group, compute the token similarity (i.e., overlap ratio) between the token sequence and the corresponding log event.
- If the maximum token similarity exceeds the threshold
st, a match is found.
- Update the parse tree:
- If a match is found: Update the corresponding log template by retaining the common tokens and replacing mismatched tokens with <*>. This step generalizes the matched template. For example:
- Matched log event:
connect to node 3. - Token sequence:
connect to node 4. - Updated log event:
connect to node *.
- Matched log event:
- If no match is found: create any missing nodes along the traversal path, and insert a new log group with the token sequence as its initial log event.
- If a match is found: Update the corresponding log template by retaining the common tokens and replacing mismatched tokens with <*>. This step generalizes the matched template. For example:
Note: Due to the constraint imposed by maxChild, each internal node may include a special <*> child that serves as a fallback during traversal.
A real example
The logparser repo provides a concise implementation of the Drain algorithm (approximately 370 lines), along with a runnable demo. In the following, we illustrat how Drain works using the HDFS_2K sample data (also included in the repo). The analysis is based on the following sampled log entries:
[1] 081109 203615 148 INFO dfs.DataNode$PacketResponder: PacketResponder 1 for block blk_38865049064139660 terminating
[2] 081109 203807 222 INFO dfs.DataNode$PacketResponder: PacketResponder 0 for block blk_-6952295868487656571 terminating
[3] 081110 103657 32 INFO dfs.FSNamesystem: BLOCK* NameSystem.allocateBlock: /user/root/rand/_temporary/_task_200811101024_0001_m_000097_0/part-00097. blk_496376132244907301
[4] 081109 205931 13 INFO dfs.DataBlockScanner: Verification succeeded for blk_-4980916519894289629Based on the observation, we may infer the following log format:
'<Date> <Time> <Pid> <Level> <Component>: <Content>'Here, the <Content> refers to the log message being analyzed. We can then define a set of regular expression patterns for normalization:
r'blk_(|-)[0-9]+'forblk_*r'(?<=[^A-Za-z0-9])(\-?\+?\d+)(?=[^A-Za-z0-9])|[0-9]+$'for digits.
[1] PacketResponder <*> for block <*> terminating
[2] PacketResponder <*> for block <*> terminating
[3] BLOCK* NameSystem.allocateBlock: /user/root/rand/_temporary/_task_<*>_<*>_m_<*>_<*>/part-<*>.<*>
[4] Verification succeeded for <*>At the beginning, the parse tree is empty. The drain algorithm (maxDepth = 4, st = 0.5) processes the first log message: PacketResponder <*> for block <*> terminating
- The log message is split into tokens using whitespace:
['PacketResponder', '<*>', 'for', 'block', '<*>', 'terminating']with length6. - Since the parse tree is empty, no match can be found. The algorithm therefore, proceeds to update the parse tree
flowchart TB
root((root)) --> six((Length 6)) --> pr((PacketResponder)) --> four_star(("<*>")) --> group1("Packet Responder <*> for block <*> terminating")
The second log message is PacketResponder <*> for block <*> terminating, which matches the log group we just created with a token similarity of 1, which is greater than st = 0.5.
Next, we consider the third log message: BLOCK* NameSystem.allocateBlock: /user/root/rand/_temporary/_task_<*>_<*>_m_<*>_<*>/part-<*>.<*>
- The log message is split into tokens using whitespace:
['BLOCK*', 'NameSystem.allocateBlock:', '/user/root/rand/_temporary/_task_<*>_<*>_m_<*>_<*>/part-<*>.', '<*>']with length11. - Since the first layer of the parse tree has no child which denotes length
11, the algorithm therefore, proceeds to update the parse tree
flowchart TB
root --> el((Length 4)) --> block((BLOCK*)) --> ns((NameSystem.allocateBlock:)) --> group2(BLOCK* NameSystem.allocateBlock:/user/root/rand/_temporary/_task_<*>_<*>_m_<*>_<*>/part-<*>.<*>)
root((root)) --> six((Length 6)) --> pr((PacketResponder)) --> four_star(("<*>")) --> group1("Packet Responder <*> for block <*> terminating")
We now examine the fourth log message Verification succeeded for <*>
- The log message is split into tokens using whitespace:
['Verification', 'succeeded', 'for', '<*>']with length4. - The first layer of the parse tree has a child that denotes length
4, but without thesucceededinternal node. The algorithm, therefore, proceeds to update the parse tree
flowchart TB
root --> el((Length 4)) --> block((BLOCK*)) --> ns((NameSystem.allocateBlock:)) --> group2(BLOCK* NameSystem.allocateBlock:/user/root/rand/_temporary/_task_<*>_<*>_m_<*>_<*>/part-<*>.<*>)
el --> succeeded((succeeded)) --> for((for)) -->group3(Verification succeeded for <*>)
root((root)) --> six((Length 6)) --> pr((PacketResponder)) --> four_star(("<*>")) --> group1("Packet Responder <*> for block <*> terminating")
At this point, we assume the Drain algorithm is now clear. The implementation is concise, and it is recommended to read the code and add print statements to observe its behavior in practice.
Wrap-up
The Drain algorithm is an online streaming log parsing algorithm that splits log messages and stores the mined pattern in a parse tree (i.e., a prefix tree). It’s simple, yet effective.
-
Jiang Z, Huang J, Yu G, et al. L4: Diagnosing large-scale llm training failures via automated log analysis[C]//Proceedings of the 33rd ACM International Conference on the Foundations of Software Engineering. 2025: 51-63. ↩︎