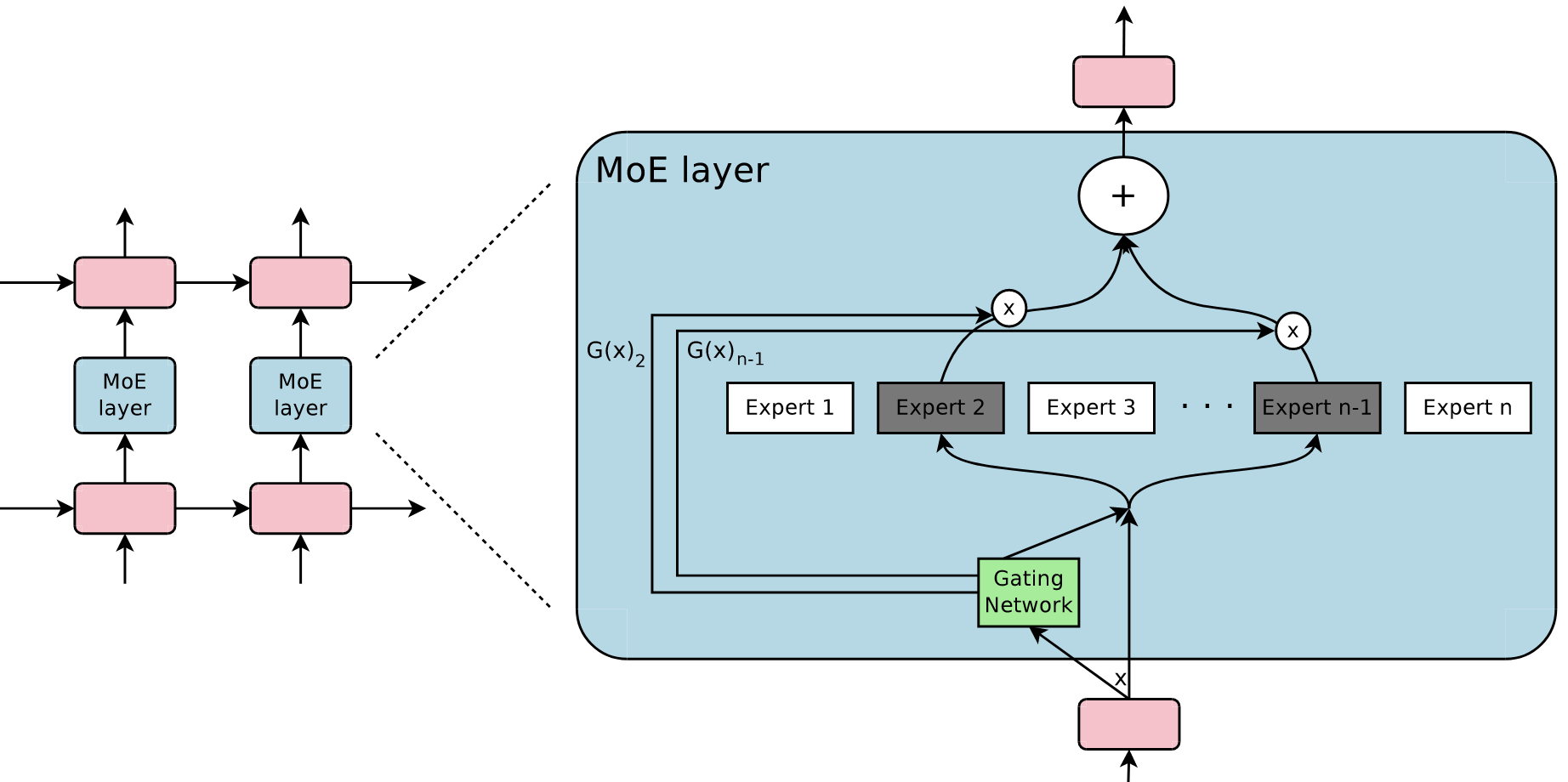
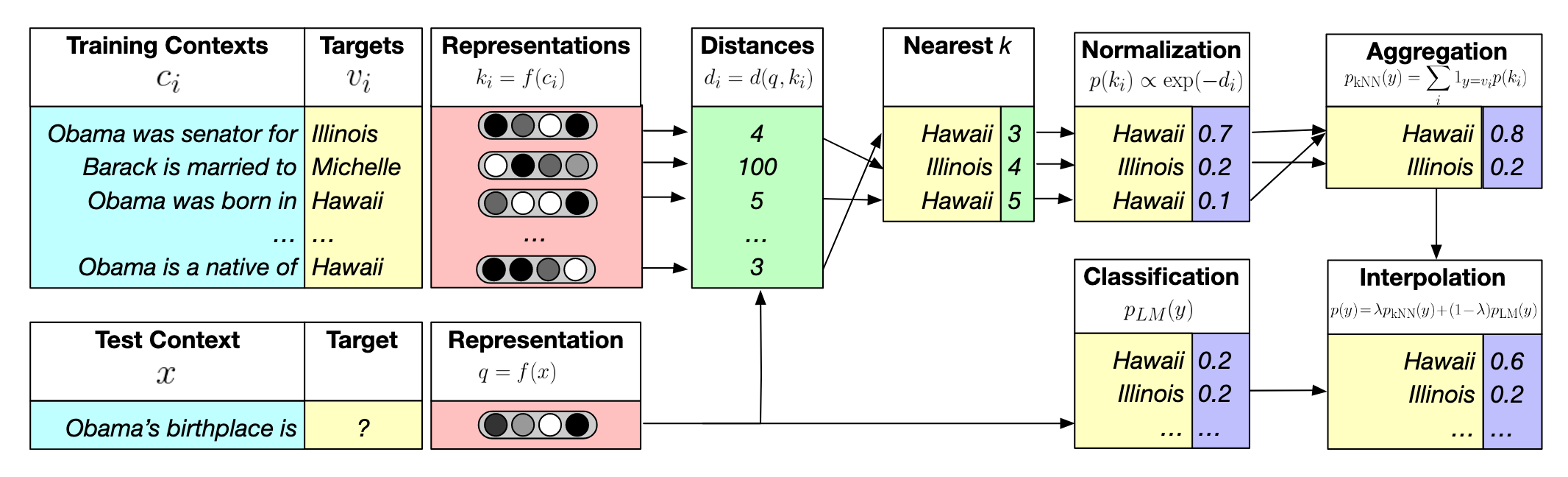
Prefix Sum Array: the secret to fast range sum query and more
Motivations
There is a type of problem where you are given an array $arr$ and $Q$ queries. Each query is represented as $query(l, r)$, which asks for the sum of the elements in the subarray $[l, r]$, i.e., $arr[l] + arr[l + 1] + … + arr[r]$.
If we handle each query using a brute-force approach, the time complexity will be $O(N)$. Thus, solving $Q$ queries would require $O(NQ)$. Is there a more efficient approach?