Vim Text Object: Semantic Editing
Updates:
Neovim Setup for OCaml
Updates:
LLM inference optimization (1): KV Cache
Updates:
LoRA fine-tuning
What’s LoRA
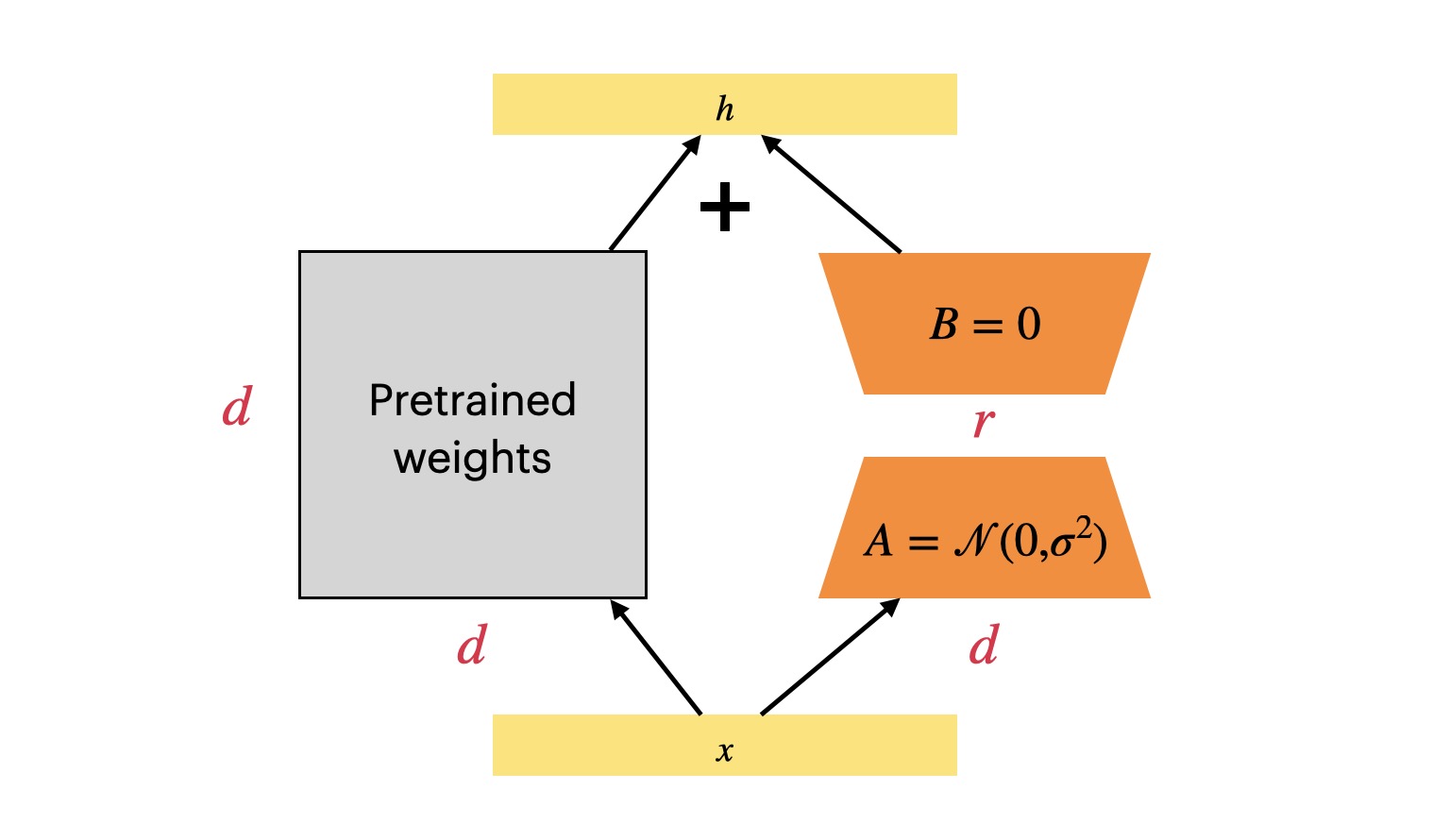
Since the era of LLM(large language model) arrived, fine-tuning LLM has become a challenge because the LLM models are extremely large, making it difficult to perform full fine-tuning. There are mainly two approaches: freeze the entire LLM and perform prompt tuning or In-context Learning; freeze the entire LLM but inserting trainable modules. Today, I will introduce the LoRA(Low-Rank Adaptation), which corresponds to the latter technical approach. This is a work proposed by the Microsoft team1
The next lexicographical permutation problem
Intro
Occasionally, you may want to get the next/prev lexicographical permutation of a sequence. How would you do that? If you are a C++ programmer, you are probably familiar with the next_permutation1 and prev_permutation2 APIs. However, Python does not provide the counterparts. So the topic today is how to do this in Python. Since the solutions of prev lexicographical permutation and the next lexicographical permutation are very similar, let us focus on the next lexicographical permutation problem.
BPE Tokenization Demystified: Implementation and Examples
You can find the BPE implementation here.
TF-IDF model
Further reading
Bag-of-Word model
What is the bag-of-word model?
In NLP, we need to represent each document as a vector because machine learning can only accept input as numbers. That is, we want to find a magic function that: $$ f(\text{document}) = vector $$
Today’s topic is bag-of-word(BoW) model, which can transform a document into a vector representation.
💡 Although the BoW model is outdated in 2023, I still encourage you to learn from the history and think about some essential problems:
A trick to calculating partial derivatives in machine learning
Intro
You may have difficulties when trying to calculate the partial derivatives in machine learning like me. Even though I found a good reference cookbook that could be used to derive the gradients, I still got confused. Today, I want to share a practical technique I recently learned from this video: when calculating partial derivatives in machine learning, you can treat everything as if it were a scalar and then make the shapes match
Demystifying PyTorch's Strides Format
Intro
Even though I have been using Numpy and PyTorch for a long time, I never really knew how they implemented the underlying tensors and why they are so efficient. Recently, while studying the course Deep Learning Systems, I finally got the opportunity to try implementing tensors on my own. After going through the process, my understanding of tensors is much better 🧐
As a PyTorch user, is it necessary to understand the underlying tensor storage mechanism? I believe it is essential. In most cases, understanding the underlying principles helps you grasp higher-level concepts better. For example, understanding the tensor storage mechanism can help you answer the following questions:
How to memorize the Red-black tree
Intro
If you are attracted by the title of this blog, I believe you may agree with me: The process of memorizing the insertion and deletion operations of the Red-black tree can be incredibly arduous. It entails keeping track of complex tree rotations and the necessity to recolor nodes as required. I once read the renowned Introducing to Algorithms written by the CLRS. However, there are so many cases to remember and I quickly get overwhelmed.
Git bundle guide
What is the git bundle command
git bundle is a relatively less commonly used git command. Its purpose is to package a git repo into a single file, which can then be used by others to recreate the original git repo. Additionally, git bundle supports incremental update. Before I learned about the git bundle command, I would usually directly use tar czf some_git_repo to create a package for a git repo. Recently, I accidentally discovered the git bundle and found it quite useful🍻.