What is stack and heap
Intro
If you’ve been using dynamic languages like Python, Javascript, etc., you probably won’t notice the difference between stack and heap. Because these languages have garbage collectors (GCs) that will automatically manage memory for you, you just need to program at a high level without considering the details. The bad news is that GC is not a cost-free design. No matter how well designed a GC algorithm is, the performance of the code will be degraded to some extent. If you have been in programming for a long time, you may have heard something like “the recursion explodes the stack”. You may or may not click on the search engine to understand the difference between stack and heap. Chances are you just clicked into this article :)
📒 Although GC will degrade the performance, it removes the mental burden of manually managing memory for developers, which can greatly speed up software development. This is sacrificing performance for development speed. However, when the performance bottleneck occurs in the later stage of the software, it is necessary to study how to refactor or even rewrite the key parts of code to improve performance.
The stack and heap I mentioned here are not the heap and stack in the data structure, but the two mechanisms of memory management. Understanding the detailed differences between stack and heap helps us understand some programming languages that are closer to the low-level, such as Rust, C, C++, etc. In Rust, the most important concept is ownership. Mastering the ownership can make you feel easier when you are learning other designs in rust😄.
The layout of a program in memory
To run a program, it must be loaded into the memory. During the process of the program running, the data also needs to be read into the memory, so have you ever wondered how all this is distributed in the memory? I will give you a rough illustration below1:
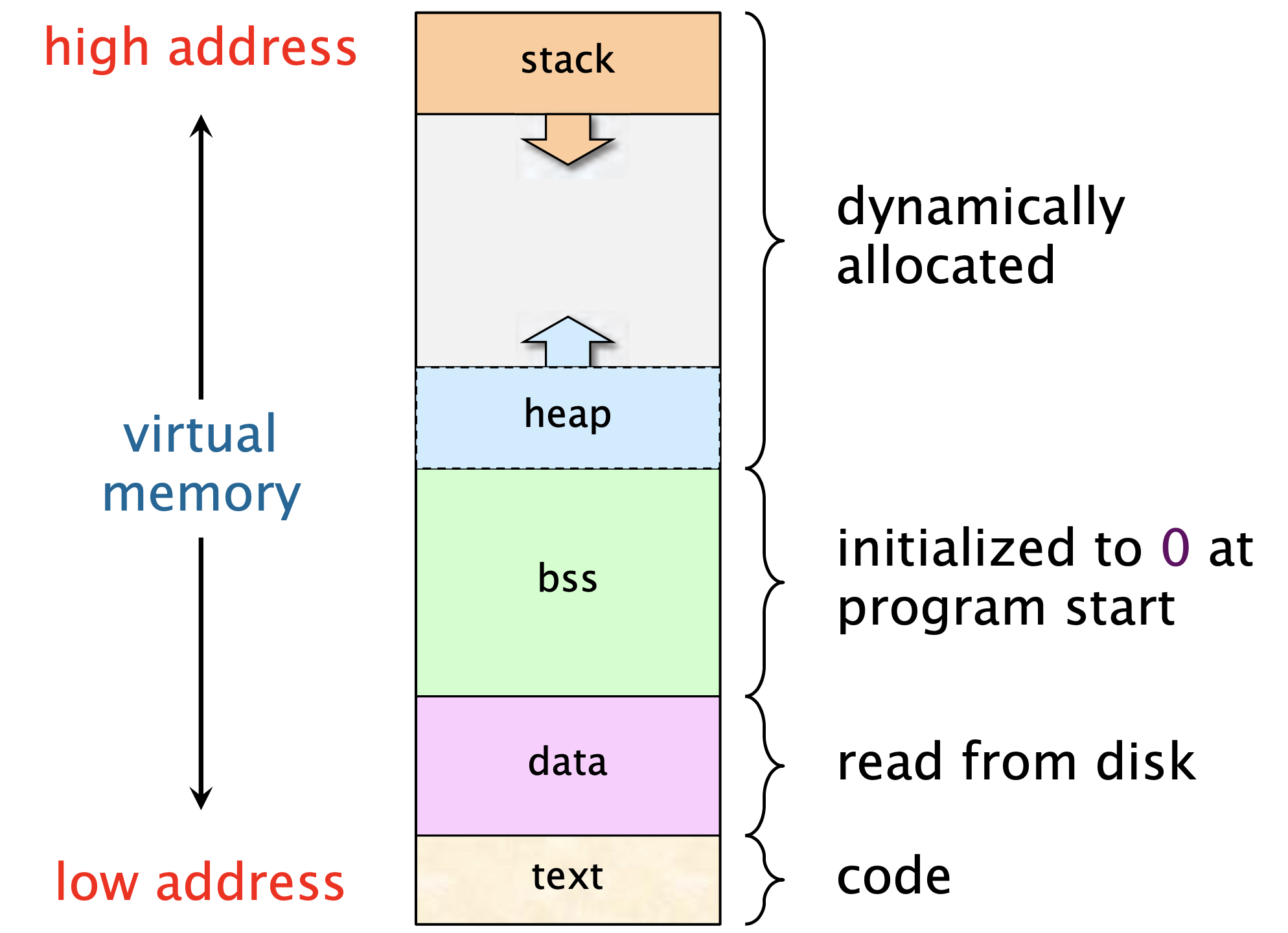
In the image above, the meanings of different parts:
- text: store code
- data: store the initialized static variables. such as global variable, static variable
- bss: store the uninitialized static data, such as the declaration
static int iin C - heap
- stack
What is stored on the heap and stack will be discussed later.
📒 The thing to remember here is that the stack and the heap are moving closer to each other as they are growing. The stack grows from high address -> low address, and the heap grows from low address -> high address. After understanding this, you will get a better understanding when you see that the
sppointer is got subtracted in the assembly code.
📒 It seems that as we allocate more and more memory, the stack and heap may collide (because they are getting closer to each other). However, there is no need to worry about this problem, because: 1) This layout is happening in virtual memory. Today’s processors are generally 64-bit, and the capacity is very large. 2) Before the conflict, it is very likely that your physical memory has been exhausted long ago, this should be your first concern.
Stack
Terms
- Stack pointer(SP): the value of a specific register, which stores the address of the top of the stack
- Stack frame: created as function calls are made, it is a frame of data(for one function call) that gets pushed onto the stack.
- push: allocating space on the stack
- pop: free space on the stack
Stack allocation
The biggest feature of the stack is the last in first out (LIFO), which is also the pattern we follow when allocating and freeing space on the stack. Allocating space on the stack is quite simple, we just need to modify the value of the stack pointer. Naturally, from the bottom of the stack (A in the figure below) to the top of the stack (the position pointed to by sp) is the space we have allocated.
The following figure1 shows the simple logic behind:
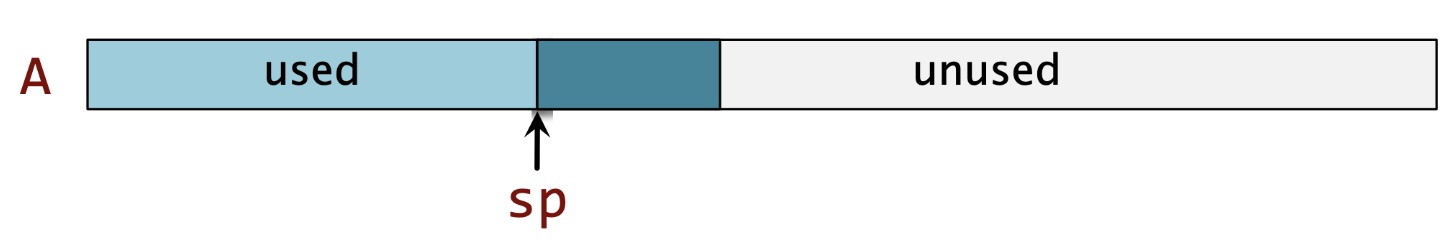
It should be emphasized again here that the stack grows from high address -> low address, so from left to right in the above figure is high address -> low address.
How does the function call work(simplified version)?
- Function call: subtract the value of
sp-> construct the stack frame for the called function, push them to the stack -> enter the callee - Function exit: just reverse the above process
The full procedure of function call can be found on 2
📒 The problem to be worried about when allocating space on the stack is: do not keep allocating which causes the stack to blow up (that is, the famous Stack Overflow problem). Keep this in mind when writing recursive functions. You can choose to implement the function in an iterative way or consider increasing the size limit of the stack. For example, in Python, you can use
sys.getrecursionlimit()to modify the size limit of the stack. In some programming languages, we can also change the recursive function to the tail recursion version, which can benefit from the optimizations.
An example: fibonacci sequence
When explaining recursion in CS courses, we usually use the Fibonacci sequence as an example. Now we use F(n) to represent the nth value of the Fibonacci sequence, then the formulas are:
F(0) = 0F(1) = 1F(n) = F(n - 1) + F(n - 2)
Take F(4) as the example, the process of the recursive function call is as follows:
F(4) = F(3) + F(2)
= F(2) + F(1) + F(1) + F(0)
= F(1) + F(0) + F(1) + F(1) + F(0)
= 3 * F(1) + 2 * F(0)If we ignore some details and illustrate the changes in the stack, it will look like this:
ps: the F(n) is a stack frame
stack: F(4)
stack: F(4) | F(3) # F(4): enter F(3)
stack: F(4) | F(3) | F(2) # F(3): enter F(2)
stack: F(4) | F(3) | F(2) | F(1) # F(2): enter F(1), F(1) is the base case, ready to exit function call
stack: F(4) | F(3) | F(2) # Function return, return to the body of F(2)
stack: F(4) | F(3) | F(2) | F(0) # F(2): enter F(0), F(0) is the base case, ready to exit function call
stack: F(4) | F(3) | F(2) # Function return, return to the body of F(2)
stack: F(4) | F(3) | F(1) # F(3): enter F(1), F(1) is the base case, ready to exit function call
stack: F(4) | F(3) # Function return, return to the body of F(3)
stack: F(4) # Function return, return to the body of F(4)
stack: F(4) | F(2) # F(4): enter F(2)
stack: F(4) | F(2) | F(1) # F(2): enter F(1), F(1) is the base case, ready to exit function call
stack: F(4) | F(2) # Function return, return to the body of F(2)
stack: F(4) | F(2) | F(0) # F(2): enter F(0), F(0) is the base case, ready to exit function call
stack: F(4) | F(2) # Function return, return to the body of F(2)
stack: F(4) # Function return, return to the body of F(4)The data on the stack
Memory space management on the stack is achieved by modifying the value of the sp pointer, so we can conclude that:
- It is very efficient when allocating or freeing the space on the stack. We can think of it as
O(1)complexity. - The logic of this LIFO of the stack is relatively simple. The compiler can shandle it for us. As developers, we do not need to intervene in this process.
- To modify the
sppointer, we need to know how much space will be used, so the data on the stack should be a fixed and known size(at compile time). As for data of variable size, this is the problem to be solved by the heap.
Heap
The disadvantage of the stack allocation is: it can not handle variable size data, and we can’t know how much the value of sp needs to be modified at this time.
How do you bridge the gap between variable-sized data and stack? This requires the use of pointers. Although the size of the actual data stored is unknown, the size of the pointer is fixed (usually, it is equal to the word size of the underlying machine), so we can store a fixed-size pointer on the stack, let it point to the real data stored on the heap.
Heap allocation
As mentioned earlier, allocating memory on the heap is finding a large enough space on the heap, returning a pointer to this location, and then pushing the pointer onto the stack.
Later, when we want to access this data, we can dereference the pointer. The * operator in C or Rust is used for this purpose. Hopefully understanding this will make it easier for you to learn pointers. :)
Unlike simply modifying the sp value on stack allocation, memory management on the heap is much more complicated. Including the following points:
- The location and size of the memory that can be allocated on the heap are arbitrary (within the physical memory size limit), we need to invent some algorithm and data structure to trace the usage. This brings great difficulties to memory management on the heap.
- The efficiency of allocating space on the heap is also relatively low. We need to find a space of sufficient size. This process of finding is more time-consuming than directly modifying the value of
sp. - We must also deal with the problem of “fragmentation”. Because the allocated space on the heap is scattered everywhere, a lot of fragments will be left in the memory in the process of heap allocation. The extreme case is: the total size of the fragments meets your requirements, but because they are scattered all over the memory and cannot be used together, the program throws an out-of-memory warning.
📒 The memory that can be allocated on the heap is way larger than the stack, but better management mechanisms are needed to handle this more complex situation. For developers, it also causes a certain burden. We can’t rely on the compiler to automatically handle it for us, we have to manage the memory manually. If you forget to call
free()after allocating space, then your program will have a memory leak problem. Not to mention other issues such as dangling pointers and double-free.
The data on the heap
After having a certain understanding of the allocation of memory space on the heap, it is not difficult for us to draw the following conclusions:
- Variable-size data is stored on the heap. More flexibility at the expense of a little performance
- Sometimes it can be fixed-size data, but you don’t want to put it on the stack. Why is this the case? For example, in Rust, data on the stack is copied by default. Sometimes for performance considerations, you may want to put large data on the heap to avoid the overhead of multiple copies. I don’t know if this reminds you of the optimization that we often did. i.e. passing function parameter by reference rather than value.
Wrap up
- Stack and heap are concepts in memory management, they are different from the concept of stack and heap in the data structure. The reason why the stack is called the stack is because we follow the classical LIFO pattern when we manage the memory on the stack, and the name of the heap implies disorganization.
- Generally speaking, it is more efficient to allocate and free memory space on the stack. For this reason, Rust operates on the stack by default.
- Data of “fixed size” is generally placed on the stack, and data of “variable size” is generally placed on the heap. However, sometimes for performance considerations, fixed-size data can also be stored on the heap.
In the subject of CS, you can often see the layered design. For example, OSI model in the computer network. Programming languages themselves can also be divided into high-level languages and low-level languages. I would like to share with you a sentence from a performance engineering teacher1 - “Many times, if you want to learn this level well, you must understand the underlying level. You don’t have to work at that level, but after knowing the details of that level. It will help you learn this level quite well”. At least for me, after knowing the difference between stack and heap, the following questions seem to me to have a very reasonable explanation:
- What are pointers in C/C++ language used for? Why do they exist?
- Why does tail recursion optimization exist? Why do we have to consider the problem of deep recursion when writing recursive functions?
- Why does Rust put data on the stack by default?
- Why did I see someone recommend passing references when implementing a function?
📒 In my humble opinion, the abstraction layer design is the most important concept in CS.
Should you choose a language with GC that is easy to use but less efficient, or choose to manually manage memory yourself to make your code more efficient? It depends on the job at hand. If you want to develop speed, of course, it is the former, and if you focus on performance, it is the latter. Of course, in the middle is no GC + basically no need to manually manage memory by yourself + efficient = Rust language 🚀. Why not learn some Rust 😉
⚠️ Some details are ignored when I write this article. I only wrote down what I think is important. If you want to learn more, you may check the refs.