LLM 推理加速技术(1):KV Cache
Info
更新:
LoRA 微调
什么是 LoRA
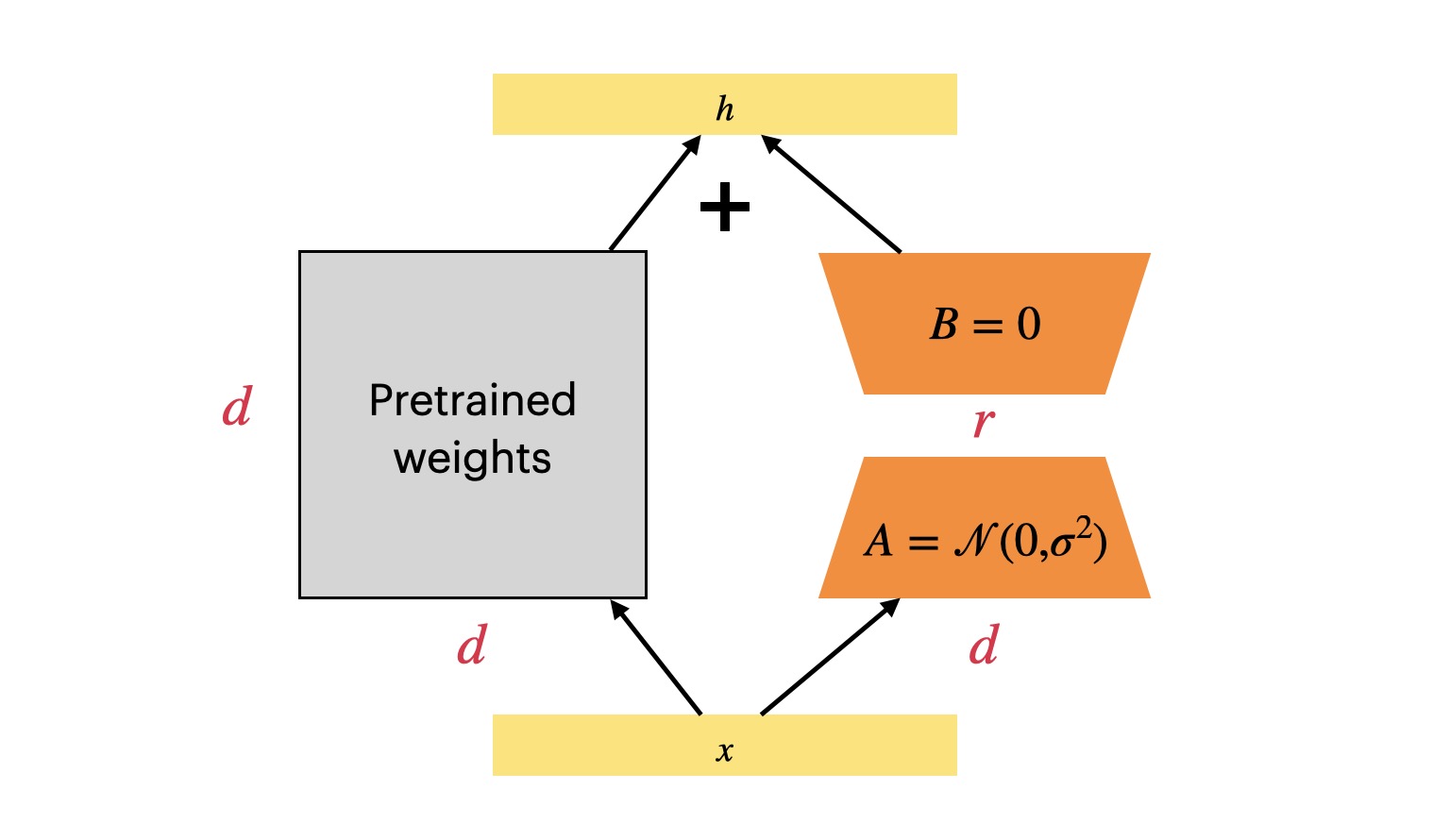
自从 LLM 时代到来之后,如何微调 LLM 成为了一个难题,因为 LLM 的模型实在是太大了,很难做全量微调更新所有参数。可选的路线有:冻结整个模型做 Prompt tuning 或者 In-context Learning;冻结整个模型但是会插入可训练的模块。今天要介绍的 LoRA(Low-Rank Adaptation) 就对应了后者的技术路线,这是微软团队的工作1